可靠性指在一定的时间和条件下,系统无故障运行的能力或可能性,一般用 MTBF (平均无故障时间)来衡量。
可靠性常作为非功能性需求在系统设计之初被边缘化甚至忽略,当我们再次提起可 靠性时,殊不知已经遭受了重大损失。云上的可靠性建设有着天然的优势:
首先,可靠性需要在架构上具备高可用性,包括应用的多可用区、多地域部署,甚 至异地多活;数据靠考虑多副本容灾能力,通过集群或分片方式提高数据的可用性。 这些作为云上的基础资源或组件,已被天然支持,唾手可得。
其次,为了进一步可靠性,云还提供了丰富的可观性能力以及自助服务。基于此, 用户可用构建多层次的可观测性能力,并基于此实现服务的故障自动发现、自动诊 断、以及自愈能力,同时通过混沌工程提前发现生产环境潜在风险。
对比于传统的 IDC,云计算的超大规模的数据中心,以及多可用区支持,让用户可 基于云以低成本、高扩展、高可靠性快速的构建同城容灾、异地容灾等服务(包括 数据)高可用方案。云计算通过虚拟化等技术对客户屏蔽了底层物理硬件,与此同 时云厂商通过虚拟化、热迁移等技术,来减少甚至规避物理硬件故障导致的服务受 损,进一步提升了用户服务的连续性以及高可用。
在可靠性上投入的成本,远比不做可靠性在产生环境代理的损失小得多。一般情况 下,高可靠性、低成本和低复杂度是一个不可能三角,更多的时候我们倾向选择提 高可靠性的前提下,在成本和复杂度上适度投入。
避免损失:根据 Statista 全球头部企业宕机损失统计,2020 年 40%的 IT 企业 宕机损失 100 万美元/小时,比如 2019 年提升 6%,17%的 IT 企业宕机损失超 过 500 万/小时,构建良好的可靠性能力最直接的收益是尽量避免此类损失。
提供确定性:好的可靠性意味着质量匀称,可以提供更长期的确定服务,得到 客户的信赖;用户可以在此基础上构建业务,更少去关心不确定的影响,专心 做好业务。
为业务增值:可靠性在某些服务业务中近似质量,在其它条件相同情况下,好 的质量有更高的价值;好的业务(服务)的稳定性是更具竞争力的表现。
云作为基础设施,由于其规模效应积累了大量业务可靠性的经验,并通过产品化方 式普惠到每个云上客户。在物理资源层,多地域提供了匀质的资源供给,方便客户 根于业务、架构和成本选择最佳资源。
在 SaaS 层,提供企业级的免运维服务,业务可以按需方便集成到系统中,基本做 到开箱即用。可靠性工程涉及部署方式、系统架构、应用拓扑和代码质量等多方面, 除了在这些层面不断引入最佳实践进行探索,也需要工程化的方式对整体业务进行 观测,并把混沌工程能力常态化引入到日常运行的业务中,做到提前、持续发现隐 患,并常态化治理。
对比于传统的运维,云厂商不仅提供了超大规模的数据中心,同时提供了全球多地 域服务,每个地域是完全独立的数据中心,多个地域之间完全独立。而每个地域又 有多个可用区,每个可用区之间电力和网络互相独立。云计算有天然的规模化和可 靠性优势。
对于可靠性要求较高的应用,通常会做同城多机房部署,避免由于单机房的网络、 电力等物理故障导致应用整体不可用。该场景下,在云上,用户可以使用同一个地 域的多个可用区来部署,通过多个可用区的互通能力来完成应用间通讯,同时多可 用区的物理隔离性极大提升了应用的容灾能力。针对多可用区部署的服务,云服务 厂商不仅会在云资源的供给上提供物理隔离的多个可用区,同时也会开放 OpenAPI能力来供用户查询并控制各个可用区可用购买的不同类型云资源,用户可用基于 OpenAPI 服务能力来构建自己的多可用区部署能力。
特大型的重要商业系统,对系统的容灾能力提出了更高的要求,同城多机房解决的 是机房维度的单点问题,无法解决某个城市因为天灾人祸导致的城市级的故障。该场景下,在云上可以使用多地域部署,另外,多地域间物理距离适当远一些,避免 单地域故障导致服务整体不可用,提升应用的极致高可用。对比于传统的 IDC 异地 容灾方案,云天然的多地域支持会极大简化用户跨地域运营服务的成本。
对于高阶用户,云服务厂商会提供 GSLB 全球负载均衡以及对应的 CDN 服务来辅助 支撑基础设施的高可用,也会提供自动化运维的 Auto Scaling 能力,用户可用通过 配置 Auto Scaling 策略来实现自动化的多地域、多可用区自动化部署,保障服务基 础设施始终处于高可靠性状态。
云服务厂商在数据的高可靠性上具备天然的优势,不仅体现在存储的多副本,数据 可靠性极高的 SLA 保障上,同时以服务化的方式向用户暴露了 OpenAPI,用户可利 用云厂商提供的快照、镜像等能力,实现数据备份容灾的高可靠性能力建设。
快照能力是云厂商提供的数据备份的核心产品能力,用户可使用快照进行系统盘、 数据盘的备份,同时支持增量备份模式,帮助客户节约存储成本。快照支持手动备 份与自动备份,推荐使用自动备份方式实现自动快照生成、轮转,对于特定业务场 景,可以通过手动方式进行指定快照生成与保留时间,也可以设置为永久保留。当 系统出现故障,需要将磁盘(系统盘或者数据盘)数据恢复到历史某一时刻,可以 使用快照回滚能力,将指定磁盘回滚,通过快照数据的恢复能力,来提升数据的容 灾能力。
同样,用户可用自定义镜像, 将快照的操作系统、数据环境信息完整的包含在镜像 中。然后使用自定义镜像创建多台具有相同操作系统和数据环境信息的实例。对于 多地容灾架构下,用户实现多地域部署时,可以使用镜像的跨地域复制能力来实现 镜像备份的分发,从而实现多地域部署情况下的数据备份。
为了帮助用户更快、更直观、更简单的发现系统内部问题,云服务厂商提供了完善 的工具与服务化能力,用户基于此来构建不同层次的可观测能力,同时利用云厂商 提供的自助服务来快速发现云资源、甚至自身业务服务的问题。
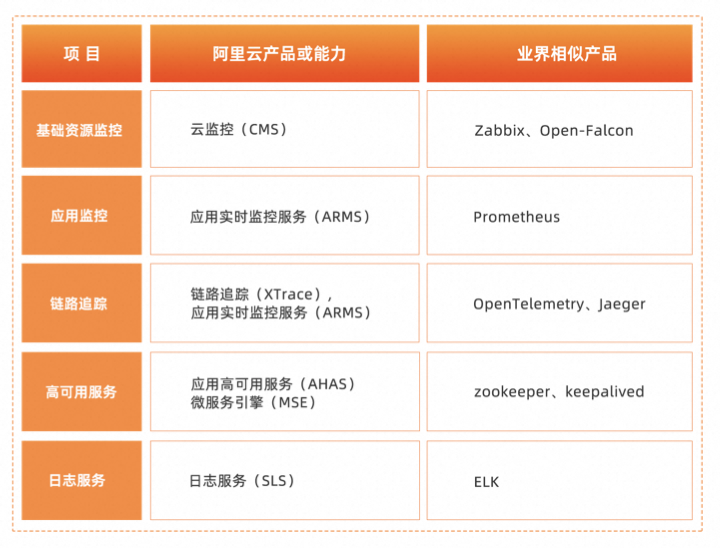
为了支持不同层次的用户需求,云厂商通常会提供以下几大类监控服务能力:云资 源监控、应用层 APM、业务层监控。
云资源监控:应用依赖的底层资源监控,比如资源的 CPU、内存、网络等指标 的使用率等。通过基础监控,用户可以自助发现云资源发生的异常,这是可观 测性最基础的能力。云厂商同时会提供云资源的诊断能力,用户可通过一键发 起对云资源的诊断,来自助发现云资源可能存在的问题。更进一步,云厂商会 提供运维事件能力,用户基于云提供的 EventBridge 事件总线,通过自动化编 排能力方式感知到云资源的异常事件,并完成自定义的自动化运维动作。
应用层 APM:基于云资源部署的具体应用场景,包括应用指标性能(Metric)、 系统调用链(Tracing)、日志监控(Logging)三个维度,比如应用的 JVM 指 标、线程池监控、RPC 服务的成功率、时延、错误率等。
业务层监控:应用层监控数据一般通过 pull/push 方式在数据聚合服务上进行 计算,产出业务指标数据。指标数据异常检测也是云上提供的一项基础服务, 用户可以选择传统的曲线异动、同比环比异常,甚至高阶的智能基线对比的自 动检测能力对业务进行监控。
云资源监控只能发现云资源的问题,对于部署在云上的大规模服务来说,应用层问 题的监控和定位能力是更加复杂和困难的。
云上需要有应用维度的监控和定位能力,在应用维度具备标准监控能力,比如服务 端应用运行时、线程池、数据库、中间件、接口调用等,在前端应用,具备从页面 打开速度(测速)、页面稳定性(JS Error)和外部服务调用成功率(API)等维度监 控页面的健康度的能力。从生态角度,这些能力要提供诸如 Prometheus、 Kubernetes 等开源产品形态。
除应用监控外,云上链路追踪 Tracing Analysis 为分布式应用的开发者提供了完整 的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,可以帮助开 发者快速分析和诊断分布式应用架构下的性能瓶颈,提高微服务时代下的开发诊断 效率。
云服务厂商会通过产品以服务化的方式来提供日志服务,用户使用日志服务做日志、 数据的采集与集成,并基于此做 Logging 和 Metering。用户通过自定义应用系统的 内容、格式,并通过日志服务收集,并在日志服务中配置自定义细粒度监控大盘, 观测自身业务运行情况,同时配置预警体系,建设用户层问题发现与定位能力。
除了在基础设施多地域部署、数据上多副本备份容灾能力外,云服务厂商通常也会提供应用服务的容错能力,帮助用户构建具备弹性、容错能力的分布式系统。
弹性容错能力:分布式系统核心的两个弹性容错能力是流控与降级,通过流控 来保护应用过载,通过降级来容忍业务部分有损换取整体可靠性。传统的流控 方式是人工判断干预,高阶的方式是通过监控体系自动发现热点流量或者异常 流量,自动化选择自适应过载保护或者设置自动降级策略并执行。
混沌工程与故障演练:混沌工程(Chaos Engineer)是一种提高分布式系统弹 性能力的工程实践,通过主动制造故障,测试系统在各种压力下的行为,在生 产环境提前识别潜在的故障,避免故障真实发生。
故障演练是遵循混沌工程实验原理的实践之一,其建立了一套标准的演练流程, 包含准备阶段、执行阶段、检查阶段和恢复阶段。通过四阶段的流程,覆盖用户 从计划到还原的完整演练过程,并通过可视化的方式清晰呈现给用户。结合观 测能力和预警能力,通过混沌工程来完成故障巡检、故障注入、以及系统稳态 度量。
设计出可靠性高的系统是一个复杂的过程,由于异常场景很多,只要稍有遗落就会 存在隐患,根据墨菲定律“可能出错的事情最终会出错”,因此推荐使用 FMEA 方 法对系统做一个全面分析。
FMEA(Failure mode and effects analysis)即故障模式与影响分析,具体分布步骤:
给出初始的架构设计图。
假设架构中某个组件发生故障。
分析故障对系统功能造成的影响。
根据分析结果(ROI),判断架构是否需要进行优化。

如果您希望对所在企业可靠性能力成熟度进行评估,建议至第十章“CloudOps 成 熟度自评”。
从基础设施可靠性、数据可靠性到应用可观测性、APM、自助诊断、弹性容错能力 等服务可靠性,阿里云都提供了完备的产品解决方案。用户可以利用这一系列能力, 提升自身服务的可靠性。
阿里云基础设施目前已面向全球四大洲,开服运营 25 个公共云地域、80 个可用区, 此外还拥有 4 个金融云、政务云专属地域,并且致力于持续的新地域规划和建设。
通过全球化的布局、超级规模的数据中心、持续的投入与深入布局来保障阿里云基础设施坚实、可靠。
从块存储技术角度,阿里云的块存储设备在具备高性能和低时延的优势下,同时提 供了极高 SLA 保障了数据的可靠性,其中云盘采用分布式三副本机制,为 ECS 实例 提供 99.9999999%的数据可靠性保证。
从数据备份与容灾恢复角度,阿里云提供了快照 2.0 技术,提供了更高的快照额度、 更灵活的自动任务策略,并进一步降低了对业务 I/O 的影响,同时增量快照能力可 以以更快的快照制作速度和更小的空间占用,帮助用户提升效率并降低成本。
用户可以通过自定义快照策略实现快照自动化备份,以极低的成本完成数据备份, 在故障场景,用户可以通过控制台或者 OpenAPI 来手动或着自动化完成快照回滚、 数据恢复。同样的原理适用于自定义镜像,用户可以通过镜像的制作、复制、恢复 来完成数据备份、中转、恢复。
自助问题排查
阿里云的基础云产品服务比如 ECS、RDS、虚拟网络均提供了云资源侧的自助诊断能力,以 ECS 和 DAS 诊断为例简单介绍。
ECS 自助问题排查:ECS 自助问题排查提供的实例健康诊断、操作异常诊 断、安全组规则检测、以及网络连通性诊断,可以全方位帮助用户诊断实例 的操作系统配置、磁盘状态、网络配置、网络状态等配置异常,同时给予修 复建议方案,帮助用户及时处理潜在风险。
数据库自治服务 DAS(Database Autonomy Service)是一种基于机器学习 和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务, 帮助您消除人工操作引发的服务故障,有效保障数据库服务的稳定、安全及 高效。
云监控 CMS
云监控服务可用于收集获取阿里云资源的监控指标或用户自定义的监控指标,探测 服务可用性以及针对指标设置警报。使您全面了解阿里云上的资源使用情况、业务 的运行状况和健康度,并及时收到异常报警做出反应,保证应用程序顺畅运行。
基础监控:云上云下统一的主机监控解决方案及百余款云产品监控。
网络监控:基于私网和公网的网络可用性监控。
业务监控:过日志监控、自定义监控把业务数据归集到云上进行统一监控和管
理。
日志服务(SLS)是云原生观测分析平台,为 Log/Metric/Trace 等数据提供大规模、 低成本、实时平台化服务。一站式提供数据采集、加工、分析、告警可视化与投递 功能,全面提升研发、运维、运营和安全等场景数字化能力作为云原生观测分析平台。
数据采集:支持 Log/Metric/Trace 统一采集,支持服务器/应用/移动设备/ 网页/IoT 等数据源接入,支持阿里云产品/开源系统/云间/云下日志数据接 入。
数据加工:通过灵活语法,在不编写代码情况下支持各种复杂数据提取、解 析、富化、分发等需求,支持结构化分析。
查询分析:提供关键词、SQL92、AIOps 函数等多种方式,支持面向文本+ 结构化数据实时查询分析,异常巡检与智能分析。
监控告警:具备丰富的可视化组件,可创建所见即所得的交互式分析大盘。 同时支持实时可编排的告警功能,可随时随地掌握业务动向。
日志审计:账户下实时自动化、中心化采集云产品日志并进行审计,支持升 级所需合规存储、查询及信息汇总报表。
投递与消费:与各种实时计算及服务实时对接,并可以实现自定义消费。支 持数据投递至存储类服务,支持压缩、自定义 Partition 以及行列等各种存 储格式。
应用实时监控服务 ARMS
应用实时监控服务(Application Real-Time Monitoring Service,简称 ARMS)是一 款应用性能管理产品,包含前端监控、应用监控和 Prometheus 监控三大子产品, 涵盖了浏览器、小程序、APP、分布式应用和容器环境等性能管理,能帮助用户实现 全栈式的性能监控和端到端的全链路追踪诊断。
实时洞察,即刻提升应用性能。前端、应用至底层机器,应用实时监控服务 ARMS 提供了完整的数据大盘监控,展示请求量、响应时间、FullGC 次数、 慢 SQL 和异常次数、应用间调用次数与耗时等重要的关键指标,时刻了解 应用程序的运行状况,确保向用户提供优质的使用体验。
全面掌握 Web 端性能数据,提供优质体验。应用实时监控服务 ARMS 前端 监控专注于 Web 端体验数据监控,从页面打开速度、页面稳定性和外部服 务调用成功率这三个方面监测 Web 页面的健康度,帮助您降低页面加载时 间、减少 JS 错误,有效提升用户体验。
Prometheus 监控,云原生时代一站式体验。应用实时监控服务 ARMS 提供 Prometheus 全托管式云服务,无需安装运维,一键开启,开箱即用监控大 盘。
链路追踪 XTrace
链路追踪(Tracing Analysis)为分布式应用的开发者提供了完整的调用链路还原、 调用请求量统计、链路拓扑、应用依赖分析等工具。能够帮助开发者快速分析和诊 断分布式应用架构下的性能瓶颈,提高微服务时代下的开发诊断效率。
分布式调用链查询诊断:同时支持微服务程序 HTTP、Dubbo、HSF 等接口 进行追踪与 PaaS 调用,如对数据库、NoSQL、MQ 等调用进行追踪。
应用性能实时汇总:可以通过跟踪整个应用程序的用户请求,来实时汇总, 组成应用程序的单个服务和资源。
分布式拓扑动态发现:可以收集您的所有分布式微服务应用和相关PaaS产 品的分布式调用信息。
应用高可用服务 AHAS
应用高可用服务(Application High Availability Service)专注于提高应用及业务的 高可用能力,主要提供流量防护、故障演练、多活容灾、开关预案四大核心能力。 用户通过各模块可以快速低成本地在营销活动场景、业务核心场景全面提升业务稳 定性和韧性。
流量监控与防护:提供包括 QPS、并发线程、响应时间(RT)、异常、CPU/load、 网络流量等指标的秒级监控能力。同时,提供应用级别的流量控制、应用间 的降级隔离、单机自适应过载保护、热点流量探测与防控、脉冲流量削峰填 谷、慢方法/SQL 的自动熔断、分布式流量控制等。
网关防护:支持 Nginx/Ingress 网关层流量控制以及 Spring Cloud Gateway、 Zuul 等常用 API gateway 的流量防护,从流量入口处拦截骤增流量,防止 下游服务被压垮。
开关预案:支持代码中配置项的动态管理,根据需求为某个应用开启或关闭 部分功能,或设置某个性能指标的阈值。通常用于设置黑白名单、运行时动 态调整日志级别、降级业务功能等场景。
混沌工程与故障演练:提供一站式架构分析、故障巡检、故障注入、系统稳 态度量等功能,帮助用户增强分布式系统的容错性和可恢复性,帮助系统平 稳上云。
多活容灾:支持分布在多个站点的系统同时对外提供服务,保障故障场景下 的业务快速恢复。横向囊括容灾架构的上线、运维、演练、切流、升级到下 线的全生命周期。纵向包含业务流量的完整路径,从流量接入,到服务化调 用,异步化消息,再到最终数据落库
《CloudOps云上自动化运维 白皮书2.0》系列文章一:前言:提出CloudOps成熟度模型CARES
《CloudOps云上自动化运维 白皮书2.0》系列文章二:CloudOps的主要衡量纬度和定义
《CloudOps云上自动化运维 白皮书2.0》系列文章三:CloudOps成熟度模型整体及等级说明
《CloudOps云上自动化运维 白皮书2.0》系列文章四:自动化能力Automation
《CloudOps云上自动化运维 白皮书2.0》系列文章五:弹性能力Elasticity
《CloudOps云上自动化运维 白皮书2.0》系列文章七:安全和合规能力Security
《CloudOps云上自动化运维 白皮书2.0》系列文章八:成本和资源量化管理能力Cost
《CloudOps云上自动化运维 白皮书2.0》系列文章九:CloudOps成熟度模型全景图
《CloudOps云上自动化运维 白皮书2.0》系列文章十:CloudOps成熟度自评
各位产业专家、引领浪潮的创业者们,阿里云正在进行“客户云支出趋势”的调研,完成10题问卷(仅需2~3分钟,每家企业限填一次),即有机会获得小礼品!
问卷请见链接:https: //survey.aliyun.com/apps/zhiliao/wvN2aaIiA
也可扫码:


2023年9月21日,阿里云正式推出阿里云创业者计划,联合知名投资机构、加速器、创服机构以及大企业创新力量,旨在为初创企业提供全方位的赋能与服务,助力创业公司在阿里云上快速构建自己的业务,开启智能时代创业新范式。
你好,我是AI助理
可以解答问题、推荐解决方案等

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论