赛题5:基于大模型的就医导诊模型评估(详细说明)
通过人工智能技术,智能导诊系统能够根据患者主诉自动分析患者的病情,并根据疾病类型和症状推荐合适的科室和医生,为患者提供精准的分诊服务。解决了传统导诊过程中可能出现的“知症不知病”、“知病不知科”以及“挂错号”等问题,大大减少了患者的等待时间和就医难度。本赛题需要在综合医院和专科医院的不同场景下,展示其在导诊应用下,通过输入主诉,得到推荐科室,以评价科室推荐的准确性。
1. 数据说明
评测数据将基于真实临床医生与患者之间关于症状、病史、医疗诉求等内容的对话构建的导诊问答题。模型需要分析对话信息,根据患者的症状和体征,为其推荐给定范围内合适的挂号科室,由于对话信息同时存在多个疑似诊断,因此输出需要覆盖所有诊断的对应科室。
评测数据集来自两类医院类型:综合医院和专科医院,专科医院又将细分为儿童、妇产、口腔、中医四类,综合医院以及每类专科医院所包含的评测数据集均被分为验证集和测试集,数据量分别为1000和1000(见表1),以保证模型在不同数据分布上的泛化能力。其中验证集将会随复赛任务发送至复赛参赛团队,团队可自行测试验证效果。测试集为复赛时进行考核的主要内容。
表1 评测数据概述
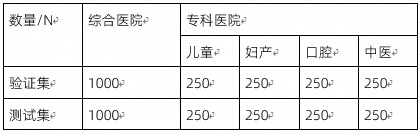
综合医院和每类专科医院均采用根据标准科室列表标注正确推荐科室答案的方式形成对应的评测数据集,点击查看:标准科室列表。
数据形式:

注:
dialoguet:是指医生与患者之间关于症状、病史、医疗诉求等内容的对话;
question:是指题干问题;
department:是指题干对应的候选科室项;
answer_department:答案内容,来自于department的一个或者多个;
sample_id:是指评测团队拟定的题号;
source:是指该题的来源途径,如综合医院、专科医院-儿童、专科医院-妇产、专科医院-口腔、专科医院-中医。
数据样例:点击下载:样例数据
case 1:

case 2:

2.成果提交
初赛需提交技术方案word版本文件1份,侧重点是对算法模型进行说明、展示真实的应用效果并提交10例包含整个对话,推荐科室结果的界面。
决赛输入待鉴别数据集:dataset.jsonl,输出识别结果:将所有识别结果整理为一份jsonl文件;同时需提交word方案、PPT汇报文件各1份,并进行方案展示。
3.评审规则
3.1初赛
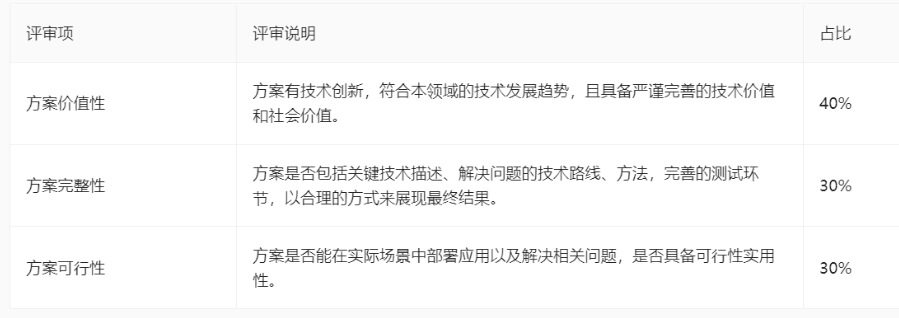
3.2决赛
对于每一次测试,只有当模型输出的答案与正确答案完全一致时,该测试才算作答正确。评测采用Accuracy作为评估指标。Accuracy是指模型预测正确数量所占总量的比例。
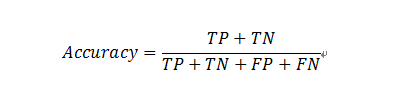

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论