当你最讨厌的人骂你时,那你一定是做对了什么
2024,对于我来说发生了两件大事:
1、小区业委会,成功换届改选
2、美国,换了新总统
上面两件事对我来说都很重要;
前者会影响小区接下来的房价走势,也算是对我前半程买房的一个交代,毕竟对绝大多数国人来说,不动产是最重要的资产配置。
后者会左右接下来几年全球局势的变化,也直接影响到我后半程的职业生涯- 股权投资 。
对于过去的2024年,该怎么去形容?我试着用几个AI大模型做搜索,得到的答案有复苏、变革、蜕变。我不是很满意,想了好半天, 只能找到一个字:麻。
麻,可以跟很多字结合,但意思却大相径庭。比如:赢麻了,又比如:麻木。
所以,麻这个字我觉得还是比较精准,包含了五味杂陈。
关于麻这个字,作为创投圈的一员,2024我的体感是:时间过得很快,但总感觉什么都没发生,仿佛失去了知觉。
欣喜的是,在一片麻木中,我还是为大家找到一了些有趣的变化,今天跟大家一起做个复盘。
1
投早、投小,拿不下三四线摇摆州
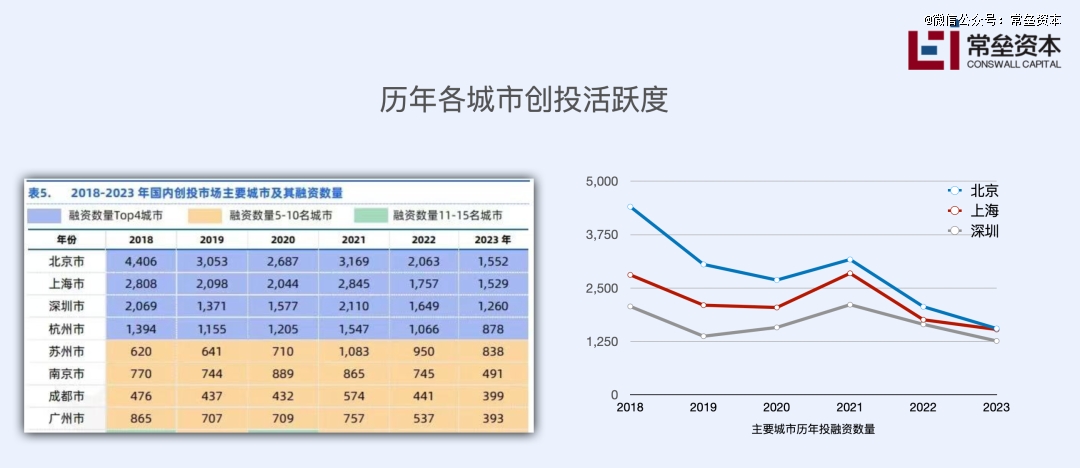
从上图可以看出过去几年的创投趋势变化。2018年的时候,北京一个城市,当年的融资数量几乎是上海和深圳的总和。经过了五年,这三个一线城市的投融资数量都在下滑,整体在逼近。
在三个城市之后,“长三角”的创投生态是碾压式的。
杭州、苏州、南京都保持了较强的活力。成都当之无愧地成为西南区域的创投聚集地,但广州的创投生态正在加速下滑。
2024年,各城市的投融资数量只会更低。
除去上面的8个城市,其余城市的创投生态其实都是非常堪忧的,不是中国的每个城市都适合做科创孵化和培育。
过去两年,我一口气跑了中国十几个城市,很多城市都是*次去。没有调查,就没有发言权。
当你真的有机会去看看,来到基层考察,你就会发现:在中国,真正具备科创生态土壤的城市,一只手*数得过来。
过去两年,很多GP管理人纷纷扎堆跟各级政府合作,一开始是看到了政府国资的大手笔。但逐渐发现,返投却成了问题。 慢慢地,政府国资开始充当投资经理”的角色,积极主动地给GP管理人推项目 。直到最近,管理人才幡然醒悟,本来想着自己用少量的社会资本,撬动政府的资金;但没想到被瓮中捉鳖,好不容易募集到的社会化资本,被国资撬动,配合去完成招商返投,原来自己变成了配资的主力。
当然国家也看到了潜在的危机。2025年一开始,国务院办公厅1号文件就出台了促进政府投资基金高质量发展的指导意见, 以后政府的投资行为跟地方招商会逐渐分离,政府投资会变得更纯粹。
如果说积压的城投债,可以靠中央化债; GP辛苦募集到的国有-民营混合基金,基金一旦到期,不知道靠谁来接手化债。
2
消失的创业者
过去两年,中国的科技企业出现了两极分化。
一方面,C轮及以后的科技企业,经历完阵痛和出清,日子慢慢好过了,因为搅局的对手基本消失了。根据晚点LatePost的最新报道,2024年,中国TOP15的互联网上市公司首次实现全部盈利,B站三季度盈亏平衡,小红书在2024年有望实现数亿美金净利润。位列头部的几家互联网巨头相较2023年,利润都有了较大提升;腾讯2024前三季度的利润已超过2023年全年,另外几家的经营业绩,甚至创造了近几年新高。
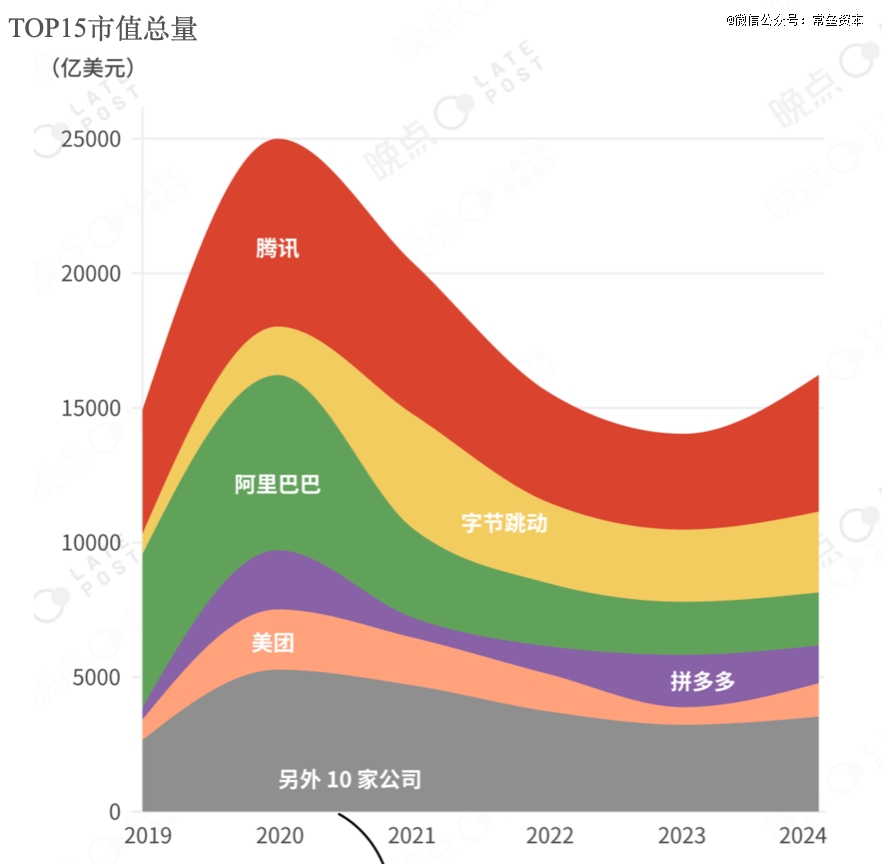
中国TOP15互联网公司市值总和变化(来自:晚点Latepost)
另一方面,A轮附近的科技企业却迎来了更残酷的考验。很多概念不错的项目,在天使轮-A轮得到追捧,人民币玩家一直疯狂A+++,之后迅速进入失重状态。 原本 A轮之后是美元VC/PE的重点狙击区,如今美元离场,成长期的科技投资变成了真空地带, 无人接盘。
这段时间,国资提到最多的就是:投早、投小、投硬,还反复提到耐心资本。但坦白说,国资真正践行投早、投小还是面临着很大的困难。
最近拜访一位体制内的老领导,他跟我说,阿矛,容错机制在我们体制内一直存在,涉及到的决策可不只是投资。 你不要只看政策怎么说,你要关注具体案例,政策到底给哪些事件容错开了绿灯 。我听完后,顿时醍醐灌顶,不得不感慨:姜,还是老的辣!
这就好比我们经常听到体制内的一句话:这件事,原则上是可以的,“但是”后面的事情,你就要细细揣摩了。
过去几年,各级政府/国资出资,以直投的方式参与到股权投资市场,初衷是响应国家号召,加速科创企业的发展,营造一个健康的创新土壤,本质并不是冲着增值保值。但股权投资基金作为一种金融产品,天生就被赋予要为后面的LP实现增值保值的重任。 当政府的公共职能遇到了资产的增值保值,很多事情就开始变得扭曲了。
自2014年开启的股权投资盛宴,陆续在2024年迎来了退出大周期。
IPO,从喷水、流水,现在是滴水
并购,路一直在,但一直找不到路
回购,这是*确定的退出路径了
一批成长期的科技企业,从估值打折,到打骨折,最后是创始人被打骨折
企业的实控人从失望、失信,再到失踪
多年后回看这段过程,他们只不过是经济浪潮滚滚向前中的沧海一粟,某种程度上他们也是经济泡沫的受害者
庆幸的是进入2025年,很多企业家逐渐从资本的恐慌中走了出来,倒不是因为企业的经营业绩出现了好转,而是他们逐渐从 质疑回购、理解回购,再到躺平迎接回购 。回购的钱一次性还不上,可以慢慢还;一旦时间拉长,你就会发现很多问题也就变的不是问题了。
与创业者一起消失的,还有加速出清的GP基金管理人。这两年身边越来越多的VC投资人转行或者被迫离场;勉强留在牌桌上的投资人,虽然习惯性地还在看项目,但出手很少(业内人称之为:刷项目);倒不是因为基金没有钱,主要是投资人都很迷茫,大家很难构建一个系统性的投资机会。多投,意味着多了一个投后的任务,也意味着不远的未来又多了一份回购追讨。
但, 再差的资本环境,仍然存在着零星的热点。
3
AI,为数不多的资本共识
AI,一条神秘的赛道
首先,无论你碰到什么样的投资人,问他最近在看什么?他都会提及AI。识趣的人,简单寒暄后,会留下一句:有好的项目,兄弟们一起投;或者也会说,有靠谱的项目我给你接盘,然后相互匆匆告别。最怕你多问一句,你觉得AI哪个方向值得投资?只要你不尴尬,尴尬的就是别人, 因为大家都没有思路。
AI,又是一条神奇的赛道
因为不同的投资人,总能在自己关注的领域,找到跟AI的交集。
看新材料的投资人 ,会研究玻璃基板散热,会关注先进封装,会关注HBM,因为这会影响GPU的性能发挥,GPU可是AI*的基石
看半导体的投资人 ,会关注数字芯片,从GPU、DPU再到XPU,很多还会关注硅光芯片、光通信,毕竟这直接关乎到底层AI算力速率
看软件的投资人 ,会关注AI+产业,俗称To B人工智能小能手。AI+工业/零售/电力/金融/教育……仿佛一切产业皆可AI化,因为再深了,确实咱也看不懂。。。
看消费的投资人 ,也重新回到了AI赛道。消费级AI电子产品,别管智能眼镜、头显、桌面电子消费品、人形机器人,一个消费品只要通电,有嵌入式代码,仿佛都可以叫AI智能终端
看先进制造的投资人 ,会关注电机、减速器、丝杠、机器人关节、灵巧手、传感器等。虽然没有魄力豪赌具身智能的本体,但一定要在具身智能的零部件身上,找到属于自己的专精特新之路
看航空航天的投资人 ,会关注低轨互联网卫星产业。毕竟AI智能终端,一旦进入地面网络覆盖稀疏的地方,想要实现云端推理,必须依靠卫星互联网
当年学习理化生基础专业的同学 ,在夹缝中也给自己找了一个新的方向,俗称 AI for Science。
当然,还有一批真正参与“AI模型六小龙”的正规军投资人,他们每天都在坚定和质疑中摇摆,毕竟字节、阿里、DeepSeek的风头太强了。
最后还有一批资本市场的场外人员 ,他们逢人就提两件事:我有便宜的算力资源,我可以带着你的产品出海。多年以后,回看这段历史,*钱的还是这批倒腾算力资源和搞出海的人,因为只有他们才真正抓住了经济学的基本原理: 真正的信息不对称,才能创造超额收益。
在100个人眼中,看到了100种AI,大家确实麻了。
4
真AI,假AI
过去一年,我们跟同行一样,刷了大量的科技项目,几乎每个BP的*页都赫然写着AI、智能体等关键词,曾经我们也一度迷茫。 AI创业项目在市场的热度,有点类似于ICU重病患者的心电图 ,横盘一段时间之后,突然跳起,因为国外TOP 3的大模型公司迭代了新版本,并流出了Demo视频,之后又会渐渐回归平静。
VC投资人疲于在各类科技媒体报道和高校实验室之间奔波,不断覆盖一个又一个热点,大家甚至都来不及思考,因为几乎每天都有爆炸性的新闻出来。
这些新闻报道的背后究竟揭示了哪些重要信息?投资人做科技投资,当然需要把握技术发展脉络,但冲在一线看Paper并不是一个明智的选择,一方面大部分投资人是很难读懂晦涩的paper,即便丢给大模型去总结;另一方面读懂70%的paper跟读不懂,区别不大,因为可能会忽略到最精髓的部分。不要用自己的热爱去挑战在实验室,用7*24精力去思考算法的AI青年研究员。
所以, AI投资最核心的事,是尽*概率覆盖圈层对的人,交叉验证这些人提供的情报脉络,再顺着脉络找到对的人,然后相信他们,按照风险偏好去下注。
一个投资前辈曾说过,投资人不需要过分研究宏观/微观,因为你很容易陷入其中。这就好比如果你想钓到一批大鱼,不需要把明尼苏达的一万个湖都搞清楚,也不需要把中国经济、世界经济都研究透彻。但是要知道哪个湖里有鱼, 哪里竞争不充分,而你又非常了解,然后在那里建立自己的能力圈,这是*投资人的核心能力。
5
AI到底发展到了哪一步
这是一个很难回答的问题,因为 你很难判断当下的热点是阶段性终结还是过程中的产物 。不过我们沿着事情的发展脉络,抽丝剥茧去观察,就像上面提到的,至少先弄清楚:本轮AI革命,到底在哪些地方真正发挥了作用。
这一代AI,会有很多概念性名词,从AIGC、AGI,再到最近的ASI 。 不管媒体怎么描述,这代AI最显著的特征就是生成式,这是有别于以往AI技术的核心思想。
生成式的实现是建立在一篇伟大的paper,那是由Google在2017年提出,题目叫做《Attention Is All You Need》的经典论文。
这代AI中,能产生巨大价值的模型,几乎都是建立在Transformer的基础架构之上,这点很重要 。
关于这篇论文,过去两年,无数的文章做了解读,我就不班门弄斧了。但综合来说, 本篇paper揭示的精髓就是:注意力机制;这个注意力涵盖了基于全局信息的表示; 与以往的CNN、RNN不同,他不做逐层或者逐步地推,而是包含了全部信息要素,主打一个简单粗暴,大力出奇迹,有点类似中国古代的智慧: 无为而治 。

值得注意的是,在上面论文署名的8位作者,自2019年开始陆续离开Google,他们要么创立了自己的AI公司,要么加入了知名的AI创业公司。 但截止到目前为止,他们并不算本轮AI浪潮的顶流创业者。 即便最著名的Character.ai,也于2024年被创始人的老东家Google按照2.5倍溢价收购,不过投资人也算赚了钱,*收场。 这再次说明,划时代的一篇研究,并不能保证一家伟大公司的诞生。
那么,到底什么样的创始人画像,才能在本轮AI竞争中胜出?
要想回答这个问题,必须先搞清本轮AI技术突破到底带来了哪些价值。我个人认为,本轮AI目前看起来已经确定的只有四个方向,接下来是最精彩的时刻,我们逐层来给大家分解。
1、大语言模型(LLM)-ChatGPT(Open AI为代表)
毫无疑问大语言模型(LLM)是本轮AI浪潮中最耀眼的一颗明珠。它是基于Transformer架构的生成式自回归模型,天然适合语言数据序列性。这套体系涵盖了训练模型和推理模型。 原本只是想在文本语义方面做的一个探索,但没想到大力出奇迹,把思维链也涌现了出来 ,这个底层的模型基座居然具备了极其强大的逻辑能力,它不但能聊天对话、还可以编程,解题,似乎无所不能,这是*的惊喜之处。
那么涌现的秘密,究竟是如何探索出来的呢?
关于Open AI,大家熟悉的,可能是上面的铁三角组合。
但在水面之下,让技术最终得以实现的,却是一群年轻人。
这里必须要提到一个至关重要的年轻人, Alec Radford 。他是GPT-1、GPT-2的*作者,是Ilya在演讲中感谢过的人,被很多人称为ChatGPT背后的真正先驱和无名英雄。

2016年,23岁的传奇AI研究员Alec Radford刚从富兰克林·欧林工程学院本科毕业 ,加盟了一家小公司Open AI。这个决定不仅仅改变了他的职业生涯,更为AI的发展掀开了崭新的一页。有人说,Radford扮演的角色,如同谷歌创始人拉里佩奇发明了PageRank。
入职OpenAI后,他开启的*个实验是,用20亿条Reddit评论训练语言模型, 最初是基于IIya sutskever在谷歌研发的Seq2Seq技术,最终以失败而告终。当时总裁Greg Brockman鼓励到,没关系,再试试吧。
但接下来,他选择了亚马逊电商平台评论,尝试让语言模型简单预测,并生成用户评论的下一个字符。
看似平凡的选择,却带来了意外的收获:模型不仅能预测评论下一个字符,还能自主判断评论的情感倾向(积极/负面),甚至还能根据要求生成不同风格的评论。
正是这个突破,引起了OpenAI前首席科学家Ilya的注意。2017 年,那篇著名论文《Attention is All You Need》发表之后,Ilya Sutskever 是少数能真正领悟 Transformer 强大之处的先驱。为什么这么说呢? 因为Transformer的出现正是击败了之前的SOTA模型:Seq2Seq,而IIya正是Seq2Seq的*作者 。 自此, Alec听从Ilya 的建议,开始尝试 Transformer 架构 ,后来他回忆说,“我在两周内取得的进展,比过去两年还要多。”
之后,Ilya跟Alec Radford一起创造了共有1.17亿参数的模型,并将其命名为「Generative Pre-trained Transformer」(GPT)。
这个模型在7000本未出版的学习书籍、Quora问答,以及各类考试文章中,展现出了前所未有的语言理解能力。 更令人惊艳的是,GPT还具备了零样本学习的能力,在未经训练的领域,同样拥有专业级水平 。这种超出预期的能力,让团队异常兴奋,同时引发了他们对AI方向的深度思考。虽然这个惊喜,在今天看来已不是什么秘密。
2019年,交易高手Sam Altman完成一项极其重要的交易,从微软手中筹集到10亿美元。
2021年,OpenAI正在构建越来越强大的模型GPT-3,并展现出了新的能力。时任OpenAI研究副总裁Dario Amodei,回忆起2018年或2019年,*次看到GPT-2时感受:我被吓到了,这太疯狂了,这在世界上是前所未有的,这种不安在2021年达到了顶点。
之后Dario Amodei与6位OpenAI同事一起离开公司,创办了Open AI*的竞争对手:Anthropic,旗下最知名的产品就是Claude。
2022年底,OpenAI发布了ChatGPT,ChatGPT在短短2个月内就达到了1亿用户,创下当时最快的用户增长记录。相比之下,TikTok用9个月,Instagram用2年半才达到同样用户规模。
ChatGPT实现了从训练模型到推理模型的飞跃, 让AI实验变成了一个可交互的应用 。这其中还有一件重要的事情,就是在预训练基础上,引入了RLHF(Reinforcement Learning from Human Feedback)
RLHF 是一种使用根据人类偏好数据训练的奖励模型来完善模型输出的工作流。常见流程包括:
•监督微调(SFT):首先在高质量数据上训练或微调基础语言模型。
•奖励模型训练:收集成对的输出结果,询问人类更喜欢哪一个,然后训练一个「奖励模型」,以接近人类的判断。
•策略优化:使用类似强化学习的算法(通常为 PPO,即「近端策略优化」)来调整 LLM 的参数,使其产生奖励模型所喜欢的输出结果。
ChatGPT在2023年正式开启商业化。
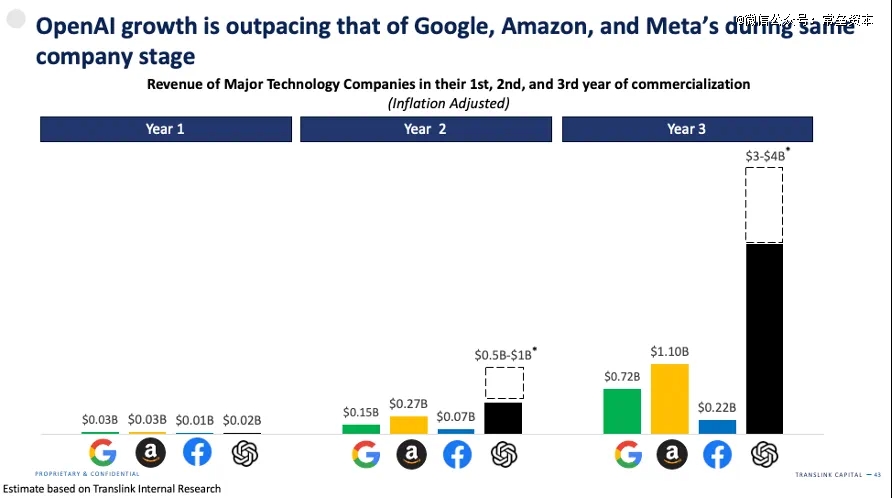

我们看到, 尽管2024年Open AI仍然每年亏损高达50亿美金,对你没看错 。不过对于一个商业化刚满两年的科技公司来说,年度取得40亿美金的收入,仍然称得上是一个奇迹,按照当前的发展进度,最快2028年Open AI可以实现盈亏平衡。需要补充的是,Dario Amodei创办的Anthropic,在2024年实现了8亿美金的年度收入,2025年1月,正在完成交割新一轮融资,估值600亿美金。
新的竞争还在继续。
最后附上红杉美国对于2025年美国AI大模型的预判:
Sequoia认为行业(美国)内已经到了Finalists阶段: OpenAI、Anthropic、Google、Meta and xAI。(是的,美国没有国内这么混乱的所谓百模大战,国内真正的基座大模型一只手就数过来了)
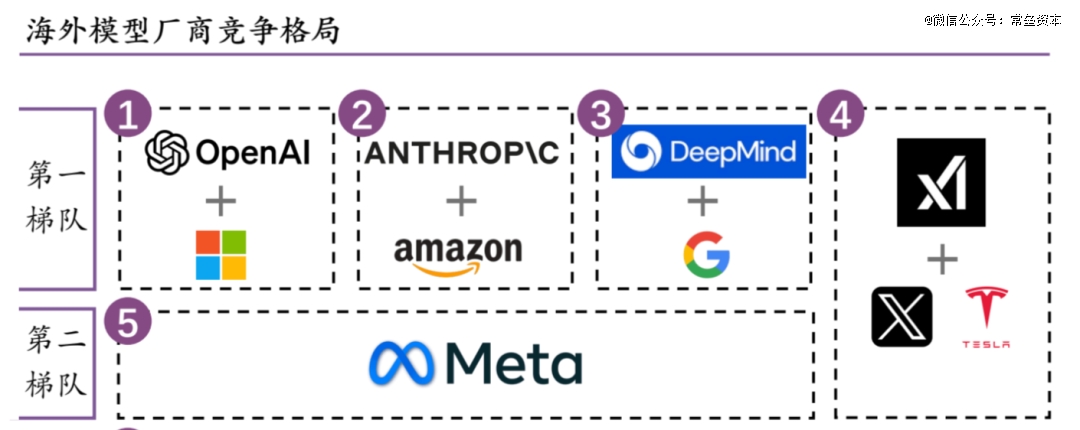
• Google: Google的优势在于其垂直整合,包括自己的AI芯片(TPUs)、广泛的数据中心基础设施和强大的内部研究团队。这种对AI价值链的端到端控制使Google能够在多个领域进行积极竞争。
• OpenAI :OpenAI在AI领域建立了强大的品牌,主要得益于ChatGPT的持续火爆。这种品牌认知转化为强大的收入引擎,使OpenAI在吸引消费者和企业客户方面具有显著优势。
• Anthropic :Anthropic的优势在于其集中了*AI人才,最近已经从OpenAI和其他*机构吸引了关键研究人员,为推动创新提供了深厚的专业知识储备。
• xAI :xAI是一门心思先把数据中心搞起来,先搞几十万H100/GB200的卡再说,其快速建设和部署大规模计算基础设施的能力对于训练和运行下一代大型AI模型至关重要,Grok据说效果也不错。
• Meta :Meta选择通过专注于开源模型来实现差异化,Llama系列模型已获得大量追随者,Meta已成为可访问性和开源社区驱动创新的倡导者。
2024年12月,全球AI顶会NeurIPS ,Ilya登场演讲,他回顾了自己过往十年在深度学习领域的经历, 最后向全世界宣告:预训练结束了! 为什么?这是因为,尽管计算能力正通过更好的硬件、更优的算法和更大的集群不断增长,但数据量并没有增长——我们只有一个互联网。甚至可以说,数据是AI的化石燃料。它们是以某种方式被创造出来的,而如今,我们已经达到了数据峰值,不可能再有更多数据了。
尽管大语言模型(LLM)横空出世,感觉无所不能,但他更像是一个高智商的“小镇做题家”, 智商或许很高,但技能还不够,很多事情仍然做得不够好,比如:像艺术总监Tony一样,做出一幅精妙的画。
2、AI生图/视频
提到AI生图,大家首先会想到扩散模型(Diffusion Model),它是一种先进的机器学习算法,它们通过逐步向数据集中添加噪声,然后学习如何逆转这一过程,独特地生成高质量数据。
其工作原理可以比喻为,画家先给一幅*的画涂上乱七八糟的颜色,让它变成了一张充满随机涂鸦的画布;然后画家通过一系列精心设计的步骤,逐渐从中清除涂鸦,最终重现出一幅详细精美的画作。
在AI的世界里,扩散模型是通过逆转扩散过程来生成新数据(一幅画)。
首先,它通过在有序的数据像素中添加随机噪声,变成无序的模糊数据像素;这个称为正向扩散过程。
正向扩散过程
然后再逆运算上述过程,把模糊随机数据恢复成原始有序的像素数据。利用这个原理反复训练,就能生成出逼近创作者意图的有序像素数据。
反向扩散过程
下图是本轮AI文生图/视频的发展历程
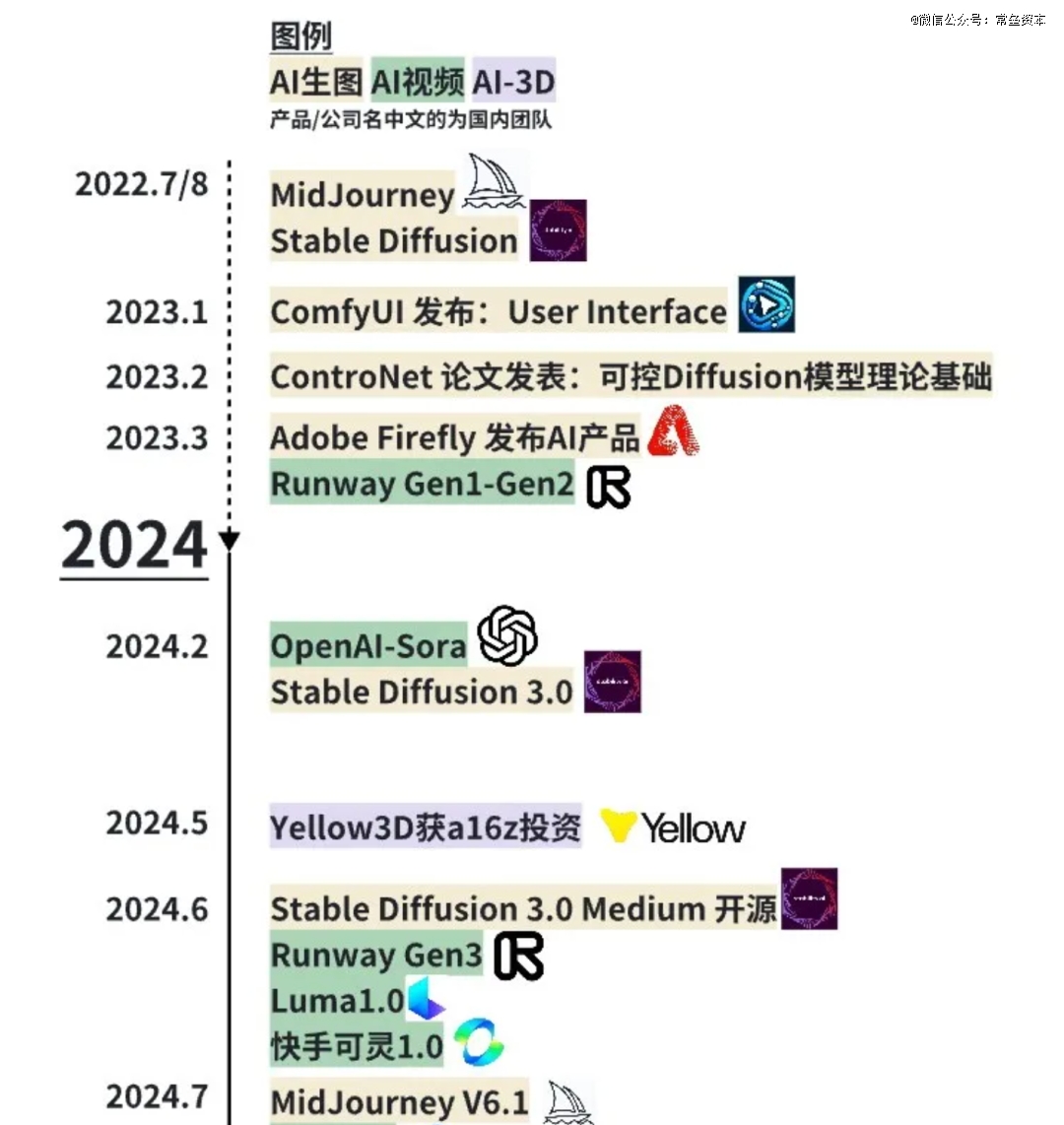
来自:《2024视觉模型鏖战:谁在吆喝?谁在赚钱?》
到24年末,视觉生成的头部玩家在算法架构上都收敛到了DiT(Diffusion Transformer)架构。
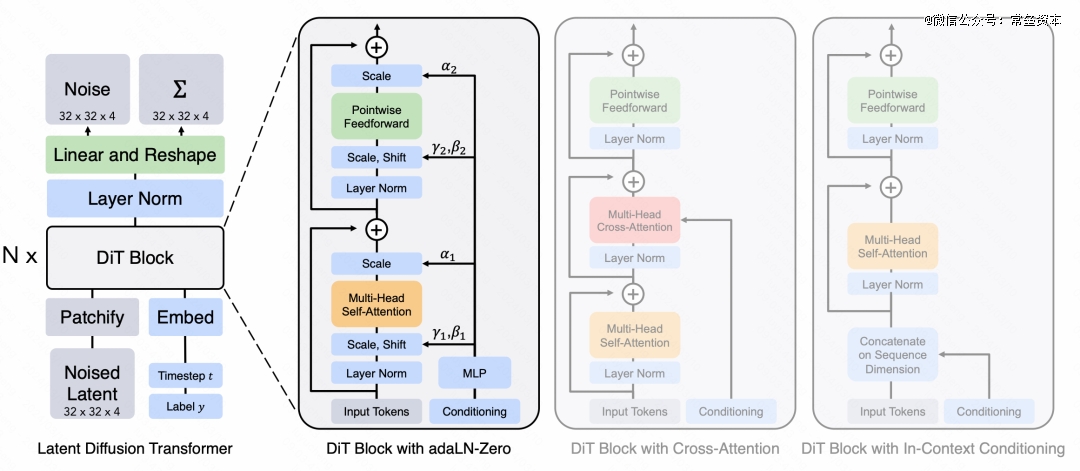
Diffusion Transformer(DiT)架构
基于 Transformers架构的 Diffusion 模型设计了一个简单而通用的基于 Vision Transformer(ViT)的架构(U-ViT),替换了 latent diffusion model 中 U-Net 部分中的卷积神经网络(CNN),用于 diffusion 模型的图像生成任务。
Transformer天然支持时序输入,而且可以并行处理多路输入,也就是说,在Unet解决不了的问题(时序+多帧输入),在Transformer(DiT)这边是比较容易解决的问题。所以越来越多的视频生成基础模型框架,会以DiT作为基础。
OpenAI的Sora背后的关键技术就是Diffusion Transformer。
纽约大学计算机科学助理教授谢赛宁(Saining Xie) 于2022年6月开始了催生diffusion transformer的研究项目 。谢赛宁(Saining Xie)与他的学生Bill Peebles一起,当时Bill Peebles还在Meta的人工智能研究实验室实习,不过现在他是Sora@OpenAI的联合负责人。
鉴于diffusion transformer的想法已经存在了一段时间,为什么像Sora和Stable Diffusion这样的项目花了数年时间才开始利用它们呢?纽约大学计算机科学教授谢赛宁认为,是因为直到最近可扩展骨干模型的重要性才被人们认识到。
还有一件有趣的事情,2024年2月,就在 Sora 发布没多久,有标题党新闻说谢赛宁是Sora的发明者之一,不过随后谢本人发了一条朋友圈澄清。谢赛宁也是一位90后,本科毕业于上海交通大学,之后在美国加利福尼亚大学圣迭戈分校完成博士学位。 不过通过他的这条朋友圈,也能窥视出国内AI发展的一些问题。

目前主流厂商既没有看到DiT的天花板,学界也还没有发明出其他被证实的更好架构。所以,最近半年的竞赛基本在算力和数据,算法层面的进展更多是微调。
既然AI可以当好艺术总监Tony,那么接下来是否有可能当一名科学家呢?
3、AI蛋白质结构预测(AI for Science)
很多人都知道今年的诺贝尔化学奖给了AI,但大都不清楚,他们仨究竟做了什么。
2024 年诺贝尔化学奖于北京时间 10 月 9 日下午 5 点 45 分揭晓。一半授予 David Baker ,以表彰其在「计算蛋白质设计」方面的贡献;另一半则共同授予 Demis Hassabis 和 John M. Jumper ,以表彰他们在「蛋白质结构预测」方面的贡献。
注意:上面三位诺奖得主,其实来自于两个流派,后面我们会做详细的说明。
蛋白质是一种分子结构。人体内的DNA提供指令,将单个氨基酸串成长链(学术上称为多肽链,一个肽链通常包含100-1000个氨基酸),一长串的氨基酸分子会自发折叠成特定形状(结构)后,就变成了 三维结构的蛋白质,它看起来有点像弹簧,但在人体内就具备了特定的功能。
人体内的蛋白质种类有几万种,它们承担着各种各样的功能:
比如:血红蛋白和肌红蛋白将氧气运输到肌肉和全身;
角蛋白可以为头发、指甲和皮肤提供结构;
胰岛素使得葡萄糖进入细胞,转化为能量;
蛋白质维持了我们人体和细胞的正常运行,它太重要了; 绝大多数时候,当一个人不舒服了,都是体内的蛋白质出现了问题 。多年来,生物学家和医药学家都在研究蛋白质的运作机理,试图找到背后的奥秘。
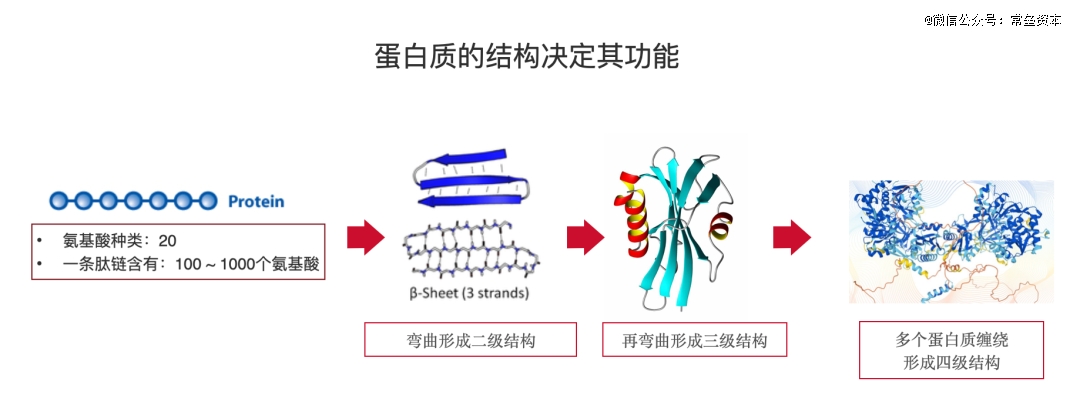
蛋白质的3D形状(结构)决定了它的功能。 一维信息的肽链如何正确折叠成特定的三维形状,这被称为 蛋白质折叠问题 。
当我们在研究一种类型的蛋白质时,得到它序列 (一维信息) 的难度,要远远低于得到它的结构形状 (三维信息)。
早在20世纪50年代,生物化学家 Christian Anfinsen取得了一个重要发现,并因此而获得了诺贝尔奖,那就是: 蛋白质的三维结构是由它的氨基酸排列顺序决定的。
到了20世纪60年代,剑桥大学的两位生物学家 Max Perutz 和 John Kendrew 将蛋白质培育成晶体,用 X 射线轰击它们,并测量射线的弯曲情况——这种技术称为 X 射线晶体学。他们用这种方法,确定了血红蛋白和肌红蛋白的三维结构, 人们首次获得了蛋白质结构 ,他们二人也因此获得了诺贝尔奖。
通常情况下,一名生物化学专业的博士生,花费4-5年的时间,就为了能研究出某类新的蛋白质结晶,从而确定其三维折叠结构。
随着更多蛋白质结构的发现,蛋白质科学界需要一种机制来研究和共享它们。1971 年,蛋白质资料库(Protein Data Bank)成立,包含了已探明的蛋白质结构,该数据库可免费使用。蛋白质资料库刚刚建立时,仅包含7种蛋白质的结构;50 年后,到 Google DeepMind 用它来训练 AlphaFold2 时,已超过 14 万个蛋白质结构——这背后是每一个结构生物学家辛苦解码得到的。
但这个速度实在太慢了。
与实验主义者不同,计算生物学家试图编写计算机算法,他们梦想着有一天,向一个软件输入一串氨基酸序列,就能输出正确的蛋白质结构。
所有人都在想,我们能否从最基本的信息:蛋白质分子的一维编码序列 (氨基酸排列), 准确预测出蛋白质分子的三维形状?
John Moult 就是其中的一位。1970年在取得了牛津大学分子生物物理学博士之后,他厌倦了实验主义者的方法,开始转向蛋白质计算领域。多年后, John Moult等人创立了结构预测关键评估(CASP)实验, 用实验确定的蛋白质结构来检验他们的蛋白质计算机模型。 没错, 这个CAPS跟大名鼎鼎的CVPR( 国际计算机视觉与模式识别会议 )一样出名,如今也走过了30年。
作为 CASP 的组织者,Moult 和 Fidelis 会发布一份蛋白质氨基酸序列列表,这些蛋白质的结构已由实验主义者探明,但结果尚未发表。然后,世界各地的计算团队会尽力使用他们的模型来预测这些蛋白质的结构。一个独立的科学家小组会对比计算的答案和实验验证的结构来评估这些模型,听起来就是一场比武切磋。
1998 年,第三届CASP比赛,一个名叫 David Baker 的年轻人凭借他的算法 Rosetta 大放异彩,它的算法可以模拟氨基酸分子原子之间的相互作用,从而预测它们如何折叠。它们“表明你确实可以预测蛋白质结构,但它不够好或不够准确,无法实用。”
2010之后,一个被称为协同进化(co-evolution)的概念被提出,后来证明对人工智能至关重要 。 通过比较数百/数千种密切相关的氨基酸序列,科学家可以识别出发生突变的氨基酸;但更重要的是, 如果两个氨基酸同时发生了突变,那么它们之间很可能存在某种联系,是的,这两个东西在空间上可能靠得很近。
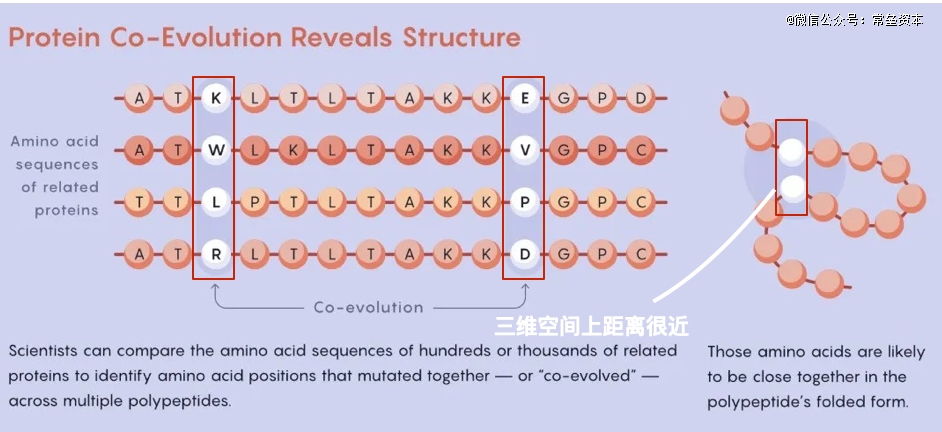
上图中白色的球代表一条肽链中的两个氨基酸,他们在同一时期发生了突变,说明在三维空间上,它们俩就离得很近。 2014 年,David Baker的算法建立在这一成功之上,Rosetta 生成了两个蛋白质结构,其准确性让一位 CASP 评估者认为 David Baker可能已经解决了蛋白质折叠问题,但似乎做得还不够好。
2017 年,Jumper 听说 Google DeepMind 正在涉足蛋白质结构预测,利用机器学习模拟蛋白质折叠和动力学。当时他刚完成芝加哥大学理论化学博士学位,就申请了一份研究科学家的工作,当年他才30岁出头。
“当时Alpha fold这个项目还是一个秘密。为了训练他们的算法,DeepMind 团队使用了蛋白质资料库中的超过 14 万多个结构。他们将这些信息输入卷积网络,但并没有对人工智能架构本身做太多改变,这是“标准的机器学习”。2018年,Alpha fold这个项目以 Google DeepMind 的名义提交结果, 最终他们取得了*名,但他们并没有取得压倒性的胜利。
后来Deepmind的创始人Hassabis,找到了John Jumper他们,并对他们说:“我们要不要全力解决这个问题? ”注:Deepmind这家公司在2014年被Google收购,旗下的Alpha Go因战胜围棋世界冠军李世石而一战成名,2023年推出大语言模型Gemini。
凭借在物理、化学、生物和计算方面的多元化背景, Jumper在头脑风暴会议上提出了一些独特的见解;很快他开始领导团队,从 6 人发展到 15 人 。在 DeepMind,统计学、结构生物学、计算化学、软件工程等领域的专家们共同解决蛋白质折叠问题。他们背后还拥有谷歌庞大的资金和计算资源。在 Jumper 的领导下,AlphaFold 被重新构建。 DeepMind 设计了一种新型的 Transformer 架构——这个架构在过去五年中“几乎推动了每一个机器学习领域的突破”。
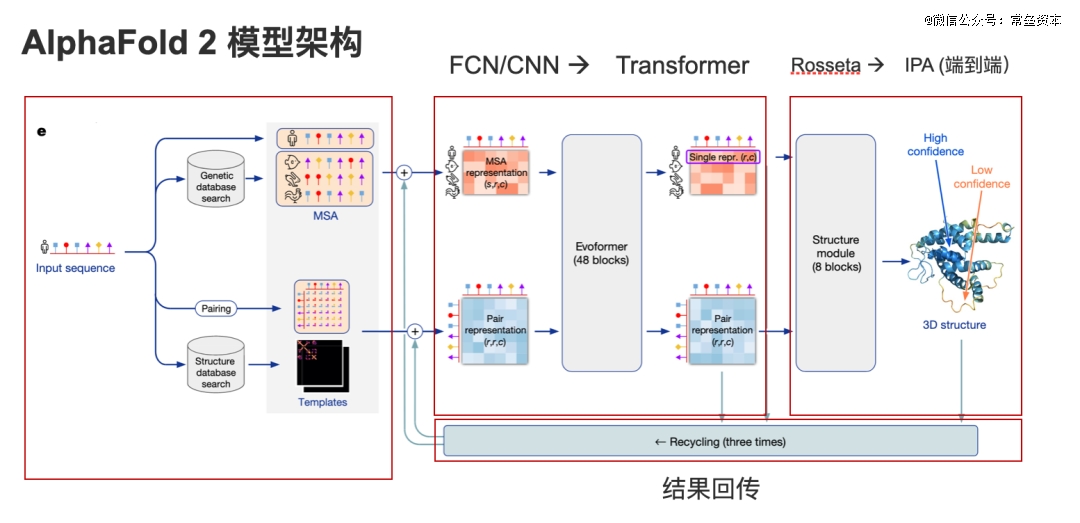
2020 年 12 月,第十四届CASP召开。每隔两年,来自全球的科学家们都会聚集在阿西洛马会议中心,这是一个位于加利福尼亚蒙特雷附近的古老教堂,他们中的许多人,穷极一生,只为在蛋白质结构预测上取得一点点进步。
每届的比赛只是带来微小的进步,人们当时没有理由认为 2020 年会有什么不同。
蛋白质科学界的新秀 John Jumper 展示了一种新的人工智能工具 AlphaFold2。 在 Zoom 会议上,他提交的数据显示,AlphaFold2 的三维蛋白质结构预测模型准确率超过 90%,比最接近的竞争对手高出五倍。
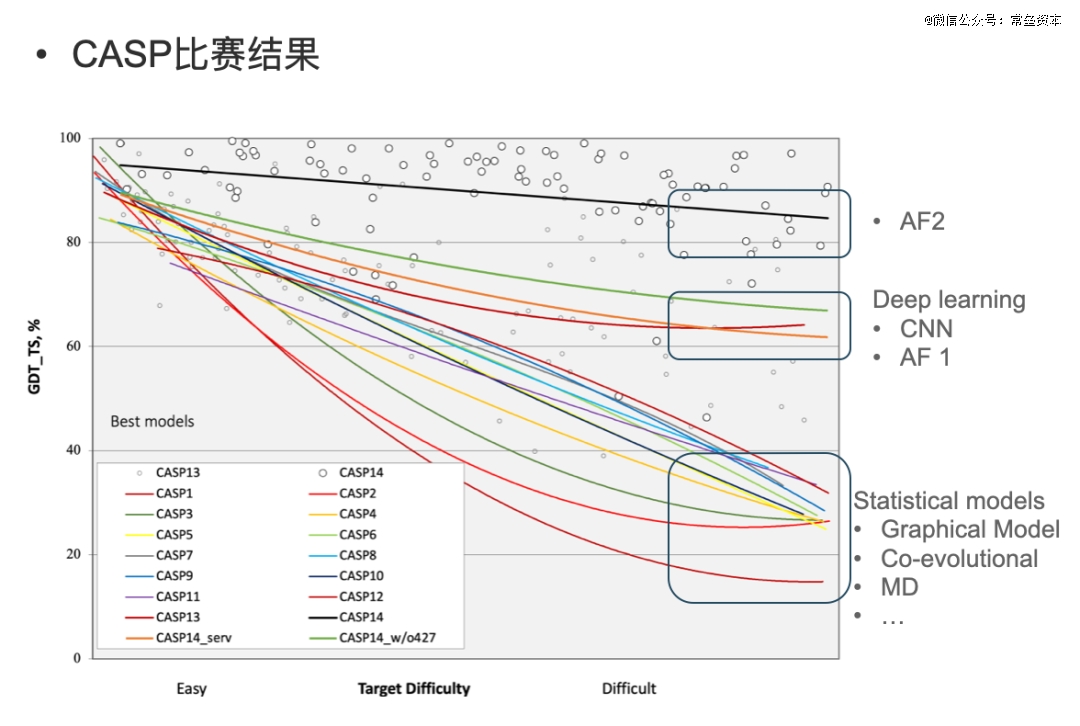
就在 DeepMind于 Nature上发表 AlphaFold2 的同一天,David Baker和他的团队发布了 RoseTTAFold,这也被认为是AlphaFold *的竞争对手。 RoseTTAFold 也使用深度学习来预测蛋白质结构,但其底层架构与 AlphaFold2 非常不同。
2024 年春天,John Jumper和David Baker 都各自更新了研究成果,分别推出了:AlphaFold3 和 RoseTTAFold All-Atom ,通过模拟蛋白质与其他分子(如 DNA 或 RNA)结合的结构,把蛋白质的研究推向了新的高度。
不过目前为止,AlphaFold3 比 RoseTTAFold All-Atom 要准确得多。 AlphaFold 3,拥有更强生成式AI模型能力,核心是引入扩散模型,采用Transformer+Diffusion,效果得到全面提升。 与现有预测方法相比,AlphaFold 3改进至少50%,可准确预测蛋白质、DNA、RNA和配体(与受体蛋白结合的任何分子)等结构以及如何相互作用,有望帮助人们治疗癌症、免疫性疾病。
2024年3月,David Baker旗下的新公司Xaira Therapeutics也获得了新一轮融资。

正是因为David Baker和John M. Jumper在蛋白质计算领域取得的不断突破,他们共同获得2024年的诺贝尔化学奖, 值得注意的一点是:John M. Jumper此时只有39岁。
不过,他们俩的竞争仍在继续。
很多人说,科学家的尽头是玄学,我觉得不完全准确,也有可能是个司机。
4、Tesla FSD
FSD,全称Full-Self Driving,它是特斯拉的全自动驾驶系统。2024年,它的V12新版本正式向社会开放,这也被称为自动驾驶领域真正“端到端”的新范式。 仅需8个摄像头,无需用上激光雷达、毫米波雷达、超声波摄像头等等其他零部件,就可以实现老司机一般的驾驶能力。
我们先看看当下市场上传统的智能驾驶方案。它们是基于Rule-Base方案:将自动驾驶分为几个步骤,分别是感知、规划、控制。先通过摄像头、激光雷达、毫米波雷达等传感器获取信息,然后基于感知结果和人为设定的规则,由自动驾驶软件代码来实现决策。
但是日常出现的驾驶情况太多了,并且还会有不常见的边缘案例(corner case)出现。它们往往非常危险,因为在算法库里,可能没有编好这种情况下的应对方案。此外, 在100种不同的驾驶场景中,你可能需要100种不同的踩刹车和加速的方法,才能达到平滑的驾驶效果,否则就很容易晕车。这就是传统方法存在的局限性。
2020 年 8 月,马斯克在推特上发文称,Autopilot 团队正对软件的底层代码进行重写和深度神经网络重构。2021年与2022年特斯拉AI Day 上 AP 团队陆续披露了相关重大突破与进展,其中主要包括:
1)2020 年 数据由人工标注转向自动标注
2)2021 年 引入 BEV(鸟瞰图)+Transformer 大 模型 ; 两者的结合帮助特斯拉完成了将八个摄像头捕捉到的2维平面图片转换为3D向量空间的工作 (也可以由激光雷达完成,但激光雷达的成本要远远高于摄像头),也解决了自动驾驶车辆对高精地图依赖的问题
3)2021 年引入时序数据;引入时序数据后, FSD 算法将使用视频片段,而不是图像来训练神经网络 , 因此可以通过先前时间段的数据特征推算当前场景下可能性*的结果
4)2022 年引入Occupancy Network(占用网络技术); Occupancy仅通过体素(3D 图像体素对应 2D 图像像素点)概念判断空间是否被占用,而并不去识别障碍物是什么。 这就显著增强了 FSD 的感知泛化能力。Occupancy Network也是通过Transformer来实现的,最终输出 Occupancy Volume (物体所占据的体积)和 Occupancy flow (时间流),也就是附近的物体占据了多大的体积,而时间流则是通过光流法来判断的。
5.)2022 年发布超级计算机 Dojo。2022 年特斯拉发布超级计算机 Dojo,其主要功能是利用海量的数据,做无人监管的自动标注和仿真训练。
下面内容是【经纬研究】马斯克“掀桌子”讲V12*的变化,在于部署了“端到端”的AI大模型。
这里面有两大关键点, 一个是端到端,一个是AI大模型 。
“端到端”简单的理解是,一端指输入端,一端指输出端,输入数据的包括摄像头的感知数据、车身的数据等等,中间通过Transformer架构的AI大模型推演之后,最终直接输出对于真实世界的理解并操控电机、刹车、方向盘。
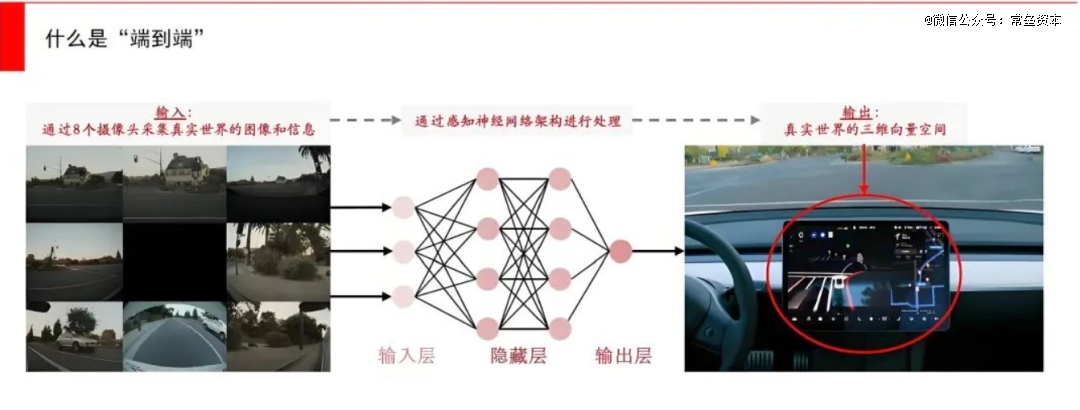
而FSD的V12版本不再需要通过代码写好“遇到红灯需要停下”,而是通过让AI观看大量人类驾驶员的驾驶视频,让AI自己找出成千上万条规律,遇到红绿灯、减速、刹车这是AI自己学会的,是自己“悟”出来的 。正是因为这样的一个转变,原来负责这一块的30万行C++代码,如今变成了3000行。这也是为什么V12版本中,FSD的驾驶表现非常拟人化。
V12跟ChatGPT这样的大模型很像,都是一个“黑盒模型”,它们需要通过足够多的数据训练,才能涌现出一些惊人的能力,并且设计它的工程师也不知道,为什么会涌现出这些能力。端到端的智驾水平主要由三大因素决定:海量的高质量行车数据、大规模的算力储备、端到端模型本身。与 ChatGPT 类似,端到端自动驾驶也遵循着海量数据×大算力的暴力美学,在这种暴力输入的加持下,可能突然涌现出令人惊艳的表现。
此外,如果训练所用的视频数据本身质量存在问题,甚至是非正常驾驶数据,那是不是训练出来的AI驾驶员就会非常危险?答案确实是。在美国,特斯拉通过北美的保险业务,延伸出了一套驾驶员行为评分系统,它会对人类驾驶员的驾驶行为严格打分。 特斯拉用于训练FSD的数据,全部来自于90分以上的驾驶员,可以说是对数据的要求极为苛刻 。
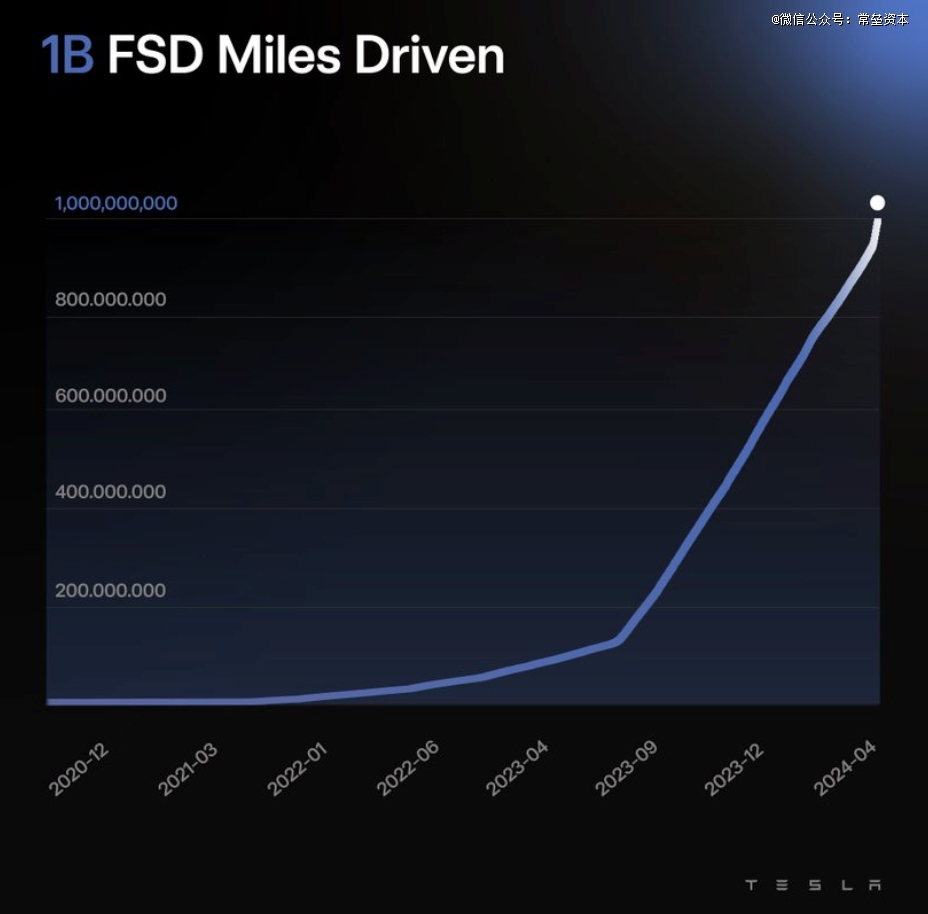
2024年上半年,Tesla FSD用户累计行驶里程已超过10亿英里
马斯克此前表示,60亿英里是FSD实现质变的重要节点。 只有推理得够多,才能知道如何对模型进行微调和优化,在自动驾驶领域重现大语言模型中Scaling law的情况,实现指数级的能力增长。如马斯克所言:当你有100万个视频片段,勉强够用;200万个,稍好一些;300 万个,就会感觉哇塞;1000万个,将变得难以置信!
2024年开始特斯拉把总算力又提高了,等同于3.5万块英伟达H100的算力,到年底还要翻倍达到8.5万块算力规模,这令特斯拉成为美国拥有*流算力规模的科技公司,与微软、Meta相当。
6
本轮AI变革,对于VC投资的启示
上面提到的四个方向,无疑都是本轮生成式AI的成功体现,也都产生了巨大的商业价值。我们在拆解的过程中,发现了一些有趣的东西,这对于VC投资还是有很强的借鉴意义
1、本轮AI技术迭代,都是建立在Transformer的基础之上,这个架构的核心就是: 用全局观的思路,暴力寻找复杂事情背后的关系,同时做出*概率的预测。 有时我们自己也在复盘,人生又何尝不是一场真人世界的概率模拟器呢?投资的胜率,又何尝不是一个良好概率模型的体现呢?所以,好的投资,还是有章可循,前提是按照概率下注。 这对于当下的国资投资也有很强的借鉴性,那就是:
- 做事要从全局思路出发,算总账
-暴力出奇迹,要给出足够的资金( 能不能给出来另当别论 )
- 概率游戏,就要给投资留出足够的容错率
2、 技术实现跃迁,并不是凭空而生或者一蹴而就的;都是依靠前人的技术积累不断迭代 ,当量变达到临界点,在对的时间就会引起质变,而且这个过程是遵循逻辑的。
Open AI走到GPT(Generative Pre-trained Transformer)这条路,也是经历了CNN、Seq2Seq不断试错,最后找到了Transformer。
Alpha fold项目能够横空出世,从早期实验学家使用 X 射线晶体学解析蛋白质结构,到计算生物学家尝试通过算法预测结构,再到协同进化观点的提出,还有过去40年众多生物化学家辛苦实验得到的十几万的蛋白质结构数据库,这些不断探索试错,最后才带来颠覆性的创新。
Tesla FSD实现端到端的突破,是从最初的神经网络HydraNet(九头蛇算法)开始,不断迭代改进,逐渐走上Transformer架构,后期借鉴大语言模型思路,一步步走到今天的无人驾驶环节。
3、自古英雄出少年
回顾这代生成式AI的发展路径,重大技术节点的突破,最终都是依靠年轻人。
Alec Radford发布初代GPT也只有25岁;
谢赛宁2022年开启diffusion transformer的研究项目时,30岁出头;
John Jumper跟团队发布Alpha fold2时,当年35岁,四年后获得了诺贝尔化学奖;
即使Sam Altman和IIya sutskever这样的顶流人物,在ChatGPT发布的时候也只有37岁,7年前的一场聚会,他俩因AI走到一起,开启了一段伟大的AGI探索之旅,当时他俩才刚过30岁。
这代AI的变革,是由一群年轻人推动的。
回顾国内市场,我们也可以看到青春的力量。
据《*财经》杂志统计,字节目前正常运营的AI应用有大约20款,其中绝大部分是在2024年以后发布的。而在模型层,2023年只正式发布了语言模型的字节,在2024年相继补全了图像、语音、音乐、视频、3D等不同模态的生成式AI模型。 在这一轮生成式AI浪潮中起步最晚的字节,已经成为目前拥有最全生成式AI模型、最多AI应用的技术公司。
但字节曾是“迟钝”的。
之前新皮层写了一篇《字节重建AI核心》的文章,里面提到CEO梁汝波在2024年初的全员会上反思道,公司“直到2023年才开始讨论GPT,而业内做得比较好的大模型创业公司都是在2018年至2021年创立的”。
其实早在2016年,张一鸣就在公司内建立了AI Lab,力邀业内多位AI专家和科学家加入。但后来随着核心团队成员的离开,字节AI Lab体系开始被进一步弱化和拆分,之后在2023年紧急成立Seed团队,某种程度上承担了AI Lab最初成立时被赋予的角色。
如今Seed团队的人数应该已经超过了150人,这还仅仅只是字节研发基础模型的团队。2023年年底, 字节又成立了一个名为Flow的团队 ,负责基于大模型的AI原生应用的研发, 豆包就是其成果之一 ,目前有近300人。
字节AI的后来居上,归功于“实际1号位”张一鸣对AI的重视,80后正值壮年的他,组织了一批最精干的人。
每一代科技巨头的成长,都是处在壮年的1号位,挖掘了一批*才华的年轻人。 字节在AI方向的追赶,像极了十多年前的那个腾讯,当时“小马哥”亲临一线,指导移动社交这场战役。
对于*爆发性的科技行业,年龄是很大的优势, 牛逼的年轻人是推动创新的关键 。所以这轮AI投资, 跟对年轻人是VC投资最重要的事 。每当技术的拐点逼近,少数最*的年轻人总是最快发现。*&牛人的马太效用,在AI时代得到了淋漓尽致的体现。 对于牌桌上的投资人,只能不断覆盖、跟随最前沿的一批年轻技术天才,然后,就是相信他们 。
4、 本轮AI创新的竞争优势 <


 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论