我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
大型语言模型 (LLM) 在处理长上下文输入方面表现出了卓越的能力,但这是以增加计算资源和延迟为代价的。我们的研究为解决长上下文瓶颈引入了一种新方法,以加速 LLM 推理并减少 GPU 内存消耗。我们的研究表明,LLM 可以在生成查询答案之前识别早期层中的相关标记。利用这一见解,我们提出了一种算法,该算法使用 LLM 的早期层作为过滤器来选择和压缩输入标记,从而显著减少后续处理的上下文长度。与标准注意和 SnapKV/H2O 等现有技术相比,我们的方法 GemFilter 在速度和内存效率方面都有了显著的提升。值得注意的是,它实现了 2.4×。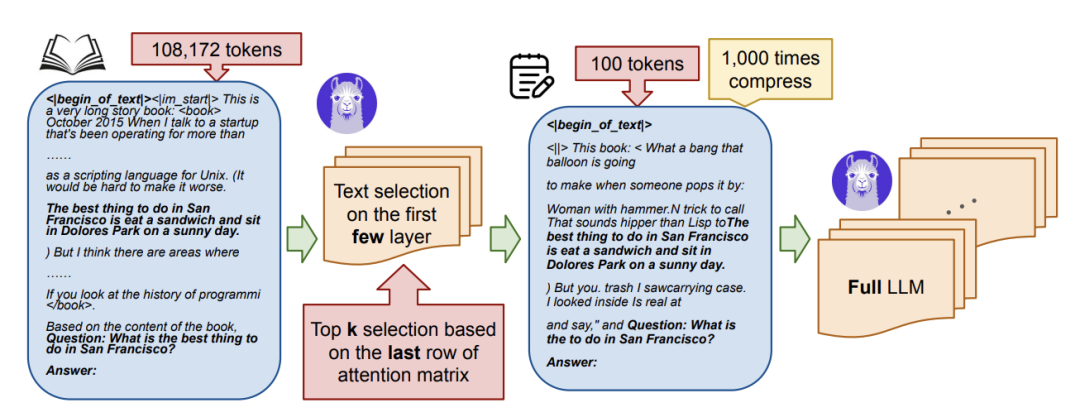 https://www.arxiv.org/abs/2409.17422
https://www.arxiv.org/abs/2409.17422
版权声明:
创新中心创新赋能平台中,除来源为“创新中心”的文章外,其余转载文章均来自所标注的来源方,版权归原作者或来源方所有,且已获得相关授权,若作者版权声明的或文章从其它站转载而附带有原所有站的版权声明者,其版权归属以附带声明为准。其他任何单位或个人转载本网站发表及转载的文章,均需经原作者同意。如果您发现本平台中有涉嫌侵权的内容,可填写
「投诉表单」进行举报,一经查实,本平台将立刻删除涉嫌侵权内容。


 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论