LLMSpace 在过去的两个月中持续追踪「潜空间」第三季全季系列活动本文中你将看到第三季中所有嘉宾的内容 Insights & 现场 Best Q&A「潜空间」第四季已经启动报名,探索更多大模型技术前沿,请扫描下方二维码参与报名。

Research Node
回顾过往的「潜空间」第三季全季四期分享内容,在多模态生成与理解、长上下序列生成、以及关于 AGI 的探索上爆发出以下的研究节点。
Event Review
第一期:Dream Machine:从视频理解 3D
1. 嘉宾简介
宋佳铭(Jiaming Song)
- 曾担任英伟达(DIR)小组科学家,创建最早的扩散模型加速算法
2. Talk 综述
本次分享介绍了 Luma AI 于 6 月 12 日发布的 Dream Machine 模型,其中重新定义了 Luma 与Sora、可灵等根本区别在于瞄准的方向为大尺度高速运动的镜头感生成,以及对于光影/色彩/速率等的超细节追求。
佳铭指出,虽然 3D 建模技术有所发展,但 3D 数据的稀缺性和可扩展性问题限制了其在生成任务中的应用。
同时提出了将 3D 生成视为 2D 生成模型下游任务的创新思路,通过对预训练的 2D 或视频模型进行微调,可以实现多视角和动态场景的生成;同时沿着此思路,加入时间维度的 4D 将有可能在复杂场景取得成功。3. 观点解析

- 自发地学习深度感知和空间结构,无需大量的三维标注数据,就能生成具有真实空间感的多视角场景。
- 能够捕捉复杂的光线传输和材质效果,如光线的反射、折射和阴影变化。通过这种数据驱动的方法,能够以更高的效率和逼真度呈现。
- 在动态性和因果关系的理解上表现出色。视频模型能够生成逼真的物体运动和场景变化,还能在镜头切换中保持角色形象和情感的连贯性。
对于生成超长时间的视频和任务中,首先要明白模型的应用场景是什么?- 模型限制:目前并不能完全离开人工,短期内,可能更多的是人与模型之间的交互和辅助;
- 实际应用:只以时长为 Benchmark 的任务极容易达成,但是效果和价值不大。
4. 原文链接
第二期:Efficient Long-context Generation
1. 嘉宾简介

陈贝迪 (Betty Chen)
- 研究方向:包含大规模的机器学习,system optimization 优化,以及如何通过 MLSys 来提升efficiency
2. Talk 综述
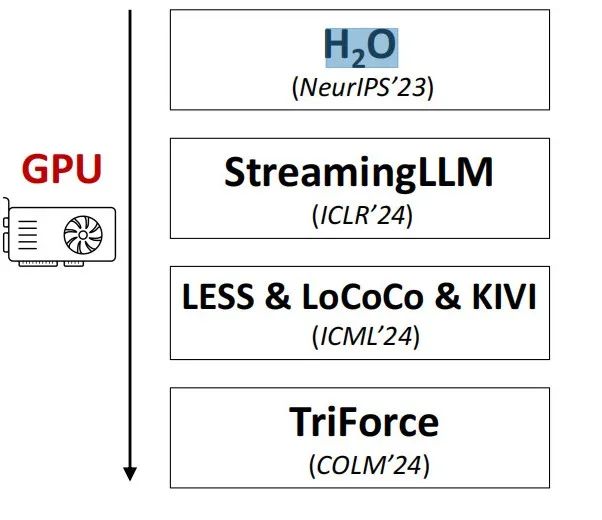
Beidi 在演讲中探讨了长上下文大语言模型在推理过程中的挑战,特别是 KV cache 带来的瓶颈。通过算法、系统和硬件的协同设计,可以在不牺牲模型能力的情况下,提升长序列生成的效率。同时分享回顾了各种提效方法,包括静态KV压缩(如H2O和StreamingLLM)、动态KV压缩和推测解码(如TriForce)。
Beidi 提出了一种新思路:不再压缩KV缓存,而是通过硬件协同设计,将其存储在更廉价的存储介质上,例如利用GPU和CPU的协同设计,充分发挥CPU的大容量存储优势,解决GPU内存限制的问题。通过使用如局部敏感哈希(LSH)等算法,系统可以高效地从CPU中检索所需的KV缓存数据,实现性能的提升。
不能够完全放弃算法的增效,如果完全依赖 GPU 提速,那么软件方面的算法就没有存在的价值。
CPU 相比于 GPU 在 deep learning 上其实是差在它的计算,同时 parallelization 很少;
我们的观察下,发现他们之间的 memory bandwidth 其实“只”差了 10 倍,为什么说“只”,因为它的计算能差几百倍。
10倍在算法加速提升上是一个 magical number。100 倍是非常难 bridge,但是 10 倍是很有可能的。
我认为现在程度的 LLM 已完全有能力应用到我们方方面面的生活中。
4. 原文链接
Beidi Chen陈贝迪 独家 | 高效长序列生成之路:CPU & GPU —— 算法、系统与硬件的 co-design
第三期:Cambrian-1:视觉在多模态大模型中扮演的角色
嘉宾简介
童晟邦(Peter Tong)
- 师从 Yann LeCun 教授和 Saining Xie 教授
2. Talk 综述
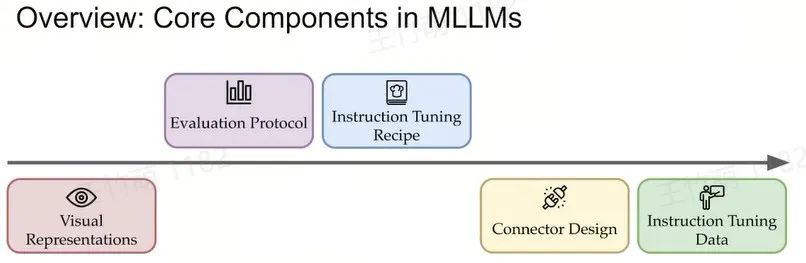
Peter Tong深入探讨了从视觉表征、评估方法、指令微调策略、连接器设计和指令微调数据五个方面详细阐述了多模态模型的发展现状和挑战。他强调,尽管当前的大模型如GPT和Claude在语言处理和知识问答方面表现卓越,但在处理视觉相关任务时仍存在不足。通过分析现有的Benchmark,提出了利用视觉领域已有的优秀数据集来构建新的Benchmark,以更准确地评估模型的视觉能力。同时,他分享了团队在开发名为“Cambrian-1”的多模态模型中的经验和发现。
3. 观点解析
我们认为AI的发展与寒武纪生命大爆炸相似。
就像当时生物从单一视觉或语言概念进化到多模态,AI也在融合多种模态。我们希望AI能够像动物长出眼睛那样,标志着一个重要进化阶段,并加速这一过程。
我认为 GPT-5 未必能实现原生的多模态功能
4. 原文链接
寒武纪视觉爆炸:多模态大模型在视觉处理中的新探索
第四期:Intelligence with Everyone
闫俊杰
MiniMax 创始人兼 CEO
中国第一梯队的大模型创业者
作为一家通用人工智能科技公司,MiniMax 致力于与用户共创智能,目前估值超 25 亿美元。公司自研了不同模态通用大模型,包括万亿参数 MoE 文本大模型、语音大模型及图像大模型,并基于不同模态大模型推出星野、海螺 AI 等原生应用,为企业和开发者提供开放平台 API 服务。
分享内容暂不公开,敬请期待!
Best Q&A
从人和自然的角度,视频理解和生成是如何被分开的呢?其背后的机制是否相同?
|
Jiaming:这可能与具体的算法设计有关。 对于理解任务,目前的研究可能更多地依赖于基于语言模型的编码器,例如LLaVA(Large Language and Vision Assistant)这样的模型,它们通过微调语言模型来进行图像编码。由于语言模型与扩散模型在算法上存在较大差异,因此从理解或生成的角度来看,它们的设计逻辑也不尽相同。因此,至少在初期阶段,人们可能还无法将这两个问题统一考虑。 |
2. 怎么看 Mamba 这一系列的这个工作?
正好前几天有一个和 MIT researcher 聊到,他说现在至少线性注意力里边,对于很多 long context 的一部分能力,其实是把它敲掉了的,然后以及你刚才提到的那个 Allen 的那一个对大模型各个能力从哪来的那个研究都是非常好的,我觉得是现在的一个研究的一个趋势。
你自己是如何理解现在的这个算法的 Architecture 的?你觉得现在的 GPU 的硬件体系下边这个 Transformer 是不是最好的模型?
|
Beidi:这个完全是我的个人选择,因为我其实早期做了挺多线性注意力这种工作的。-
版权声明:
创新中心创新赋能平台中,除来源为“创新中心”的文章外,其余转载文章均来自所标注的来源方,版权归原作者或来源方所有,且已获得相关授权,若作者版权声明的或文章从其它站转载而附带有原所有站的版权声明者,其版权归属以附带声明为准。其他任何单位或个人转载本网站发表及转载的文章,均需经原作者同意。如果您发现本平台中有涉嫌侵权的内容,可填写 「投诉表单」进行举报,一经查实,本平台将立刻删除涉嫌侵权内容。
|










 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍

评论