
在讲解技术前,先介绍我们的工作“Cambrian-1”。“Cambrian”指寒武纪生物大爆炸的时期。
你可能好奇,动物何时开始长出眼睛?GPT告诉我,约5.41亿年前的寒武纪时期,动物才开始长出眼睛。在这个生物大爆炸阶段,生命从简单形态演变为多样化的生态系统。

来源:寒武纪图片
我们的研究动机来源于此。
我们认为AI的发展与寒武纪生命大爆炸相似。就像当时生物从单一视觉或语言概念进化到多模态,AI也在融合多种模态。我们希望AI能够像动物长出眼睛那样,标志着一个重要进化阶段,并加速这一过程。
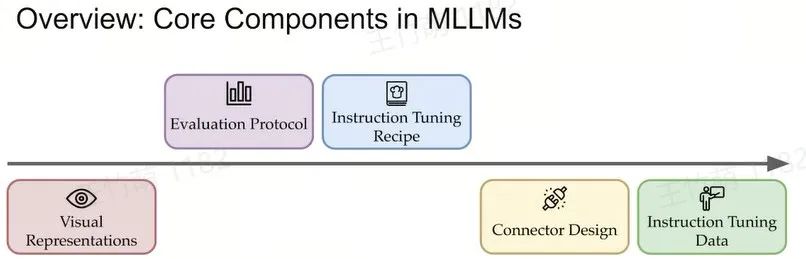
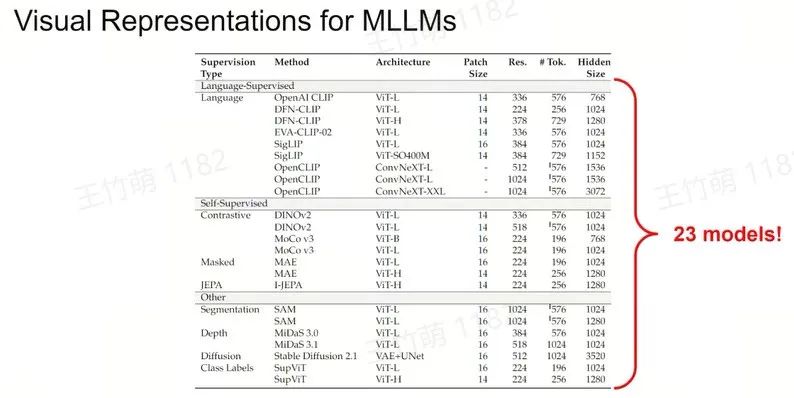
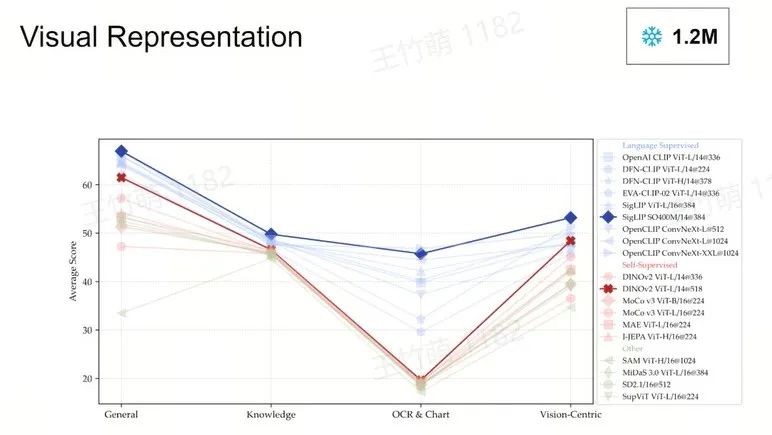
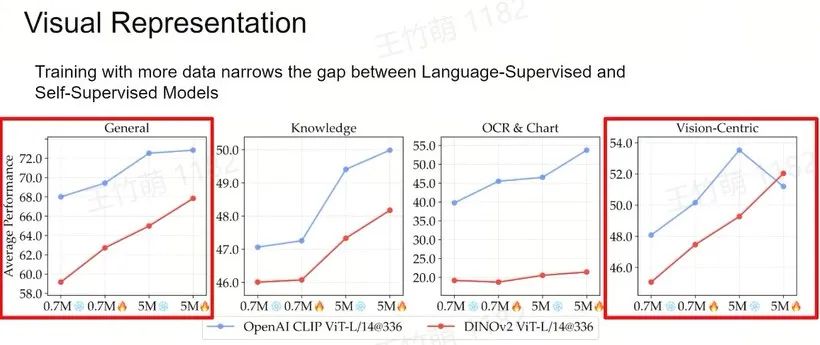
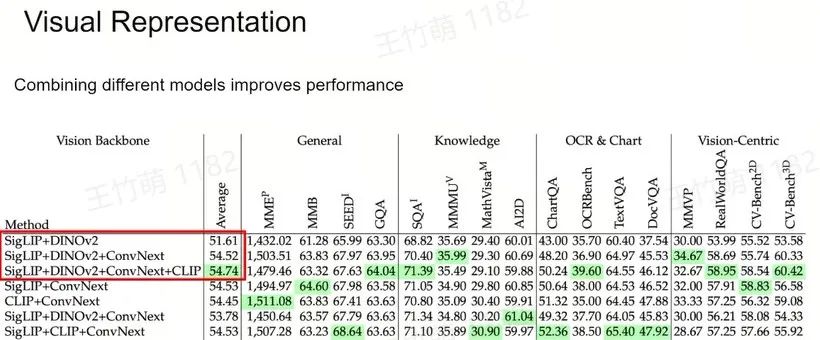
所以我们主要关注排除 LLM 外标红的5个方面,也就是到底该采用何种视觉表征和视觉主干网络(Vision Backbone),如何实现视觉与语言的有效连接,使用何种数据进行连接,以及如何对模型进行评估。
如今,许多杰出的研究和研究人员已经完成大量评估工作,我们希望帮助了解模型的性能优劣。
为何研究视觉?
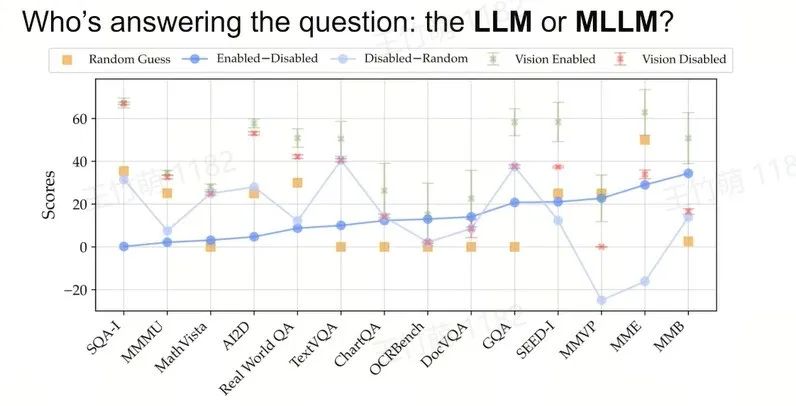
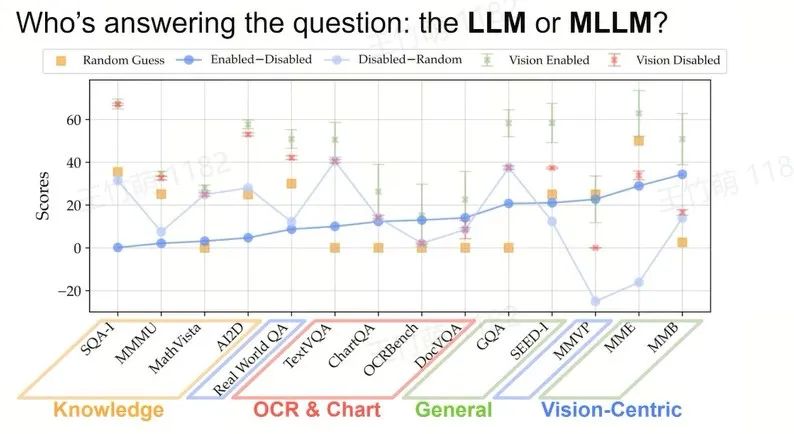
如果我们观察一些经典的 Benchmark,如 MMLU、MASH 和 GPQA,发现模型的改进已经日益增多,尤其在知识方面表现出色,但是同时它们可能会犯一些非常简单的错误。
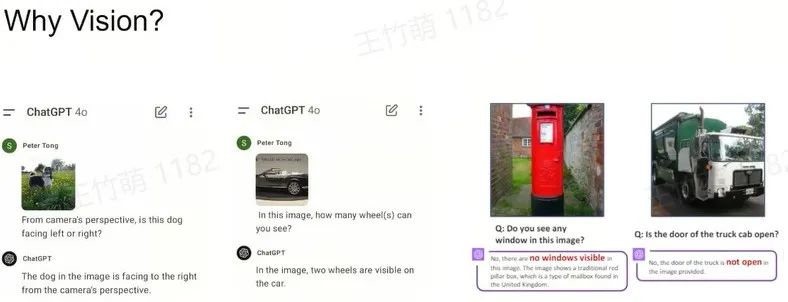
比如在最新的 GPT-4o 模型中,问它狗狗是面向左还是右,它会回答错误;问它图中有几个轮子,它会答错。这不仅是 GPT,其他模型如 Gemini 和 Claude 3.5 Sonnet 也存在类似问题。
虽然这些问题看似简单,但是模型却持续出错。
如果你询问Claude有几个轮子,它会回答两个轮子;如果询问Gemini,答案更加离谱,有16个轮子。
我们想了解在模型能解答许多复杂问题的同时为何还会犯这些小错误?这些小错误是否会影响我们后续真正使用这些模型?因为我们使用这些模型的目的并不一定是解决复杂问题,可能只是想让它完成一些基础简单的任务,做出非常基本的判断。
我将从以下五个方面讲述 MLLMs 的发展:
Visual Representations
Evaluation Protocol
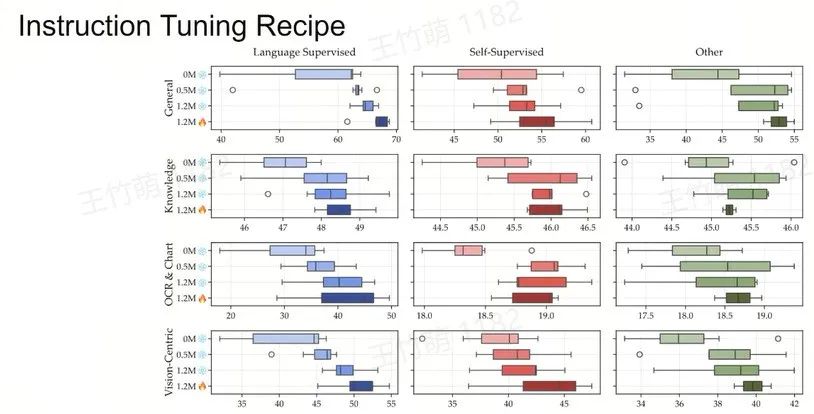
Instruction Tuning Recipe
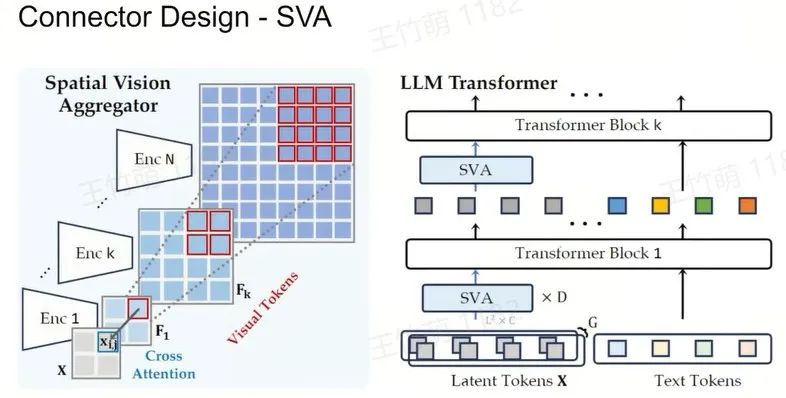
Connector Design
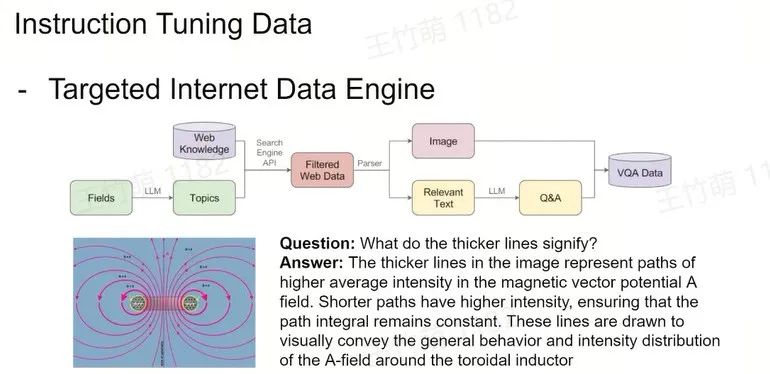
Instruction Tuning Data


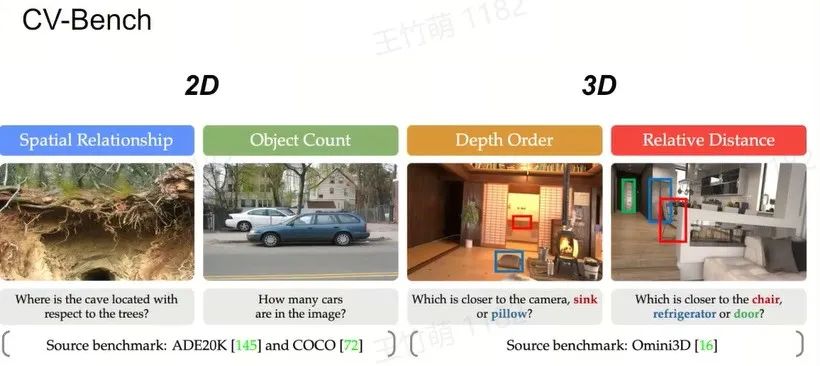
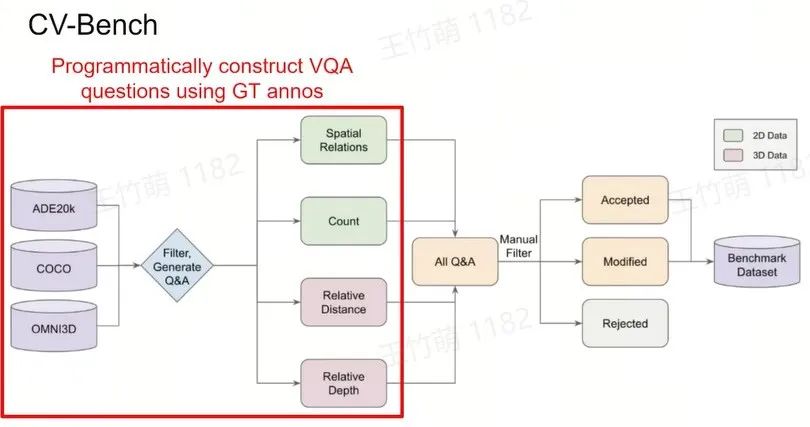
Benchmark Analysis
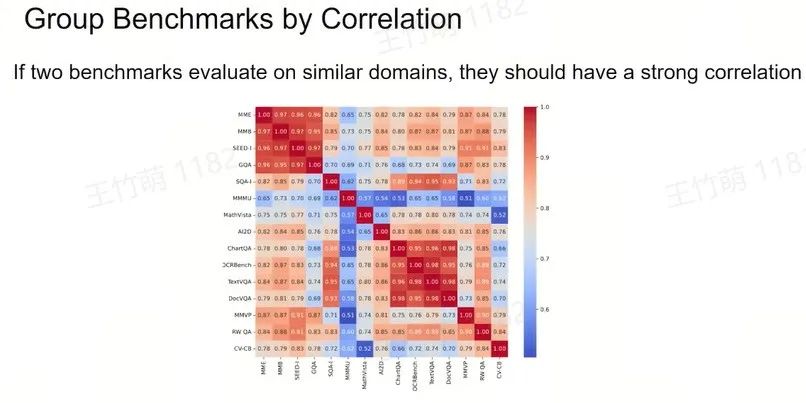
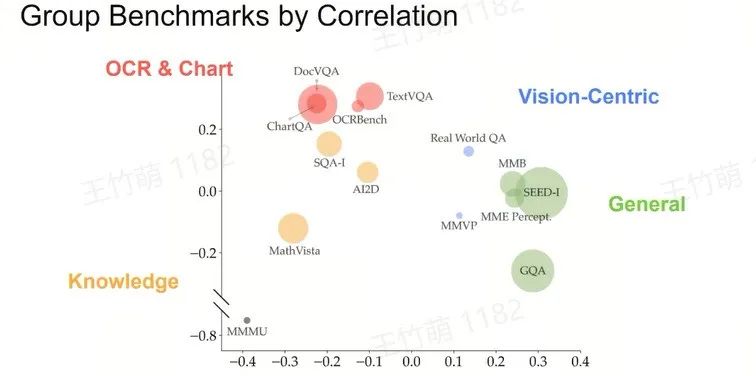
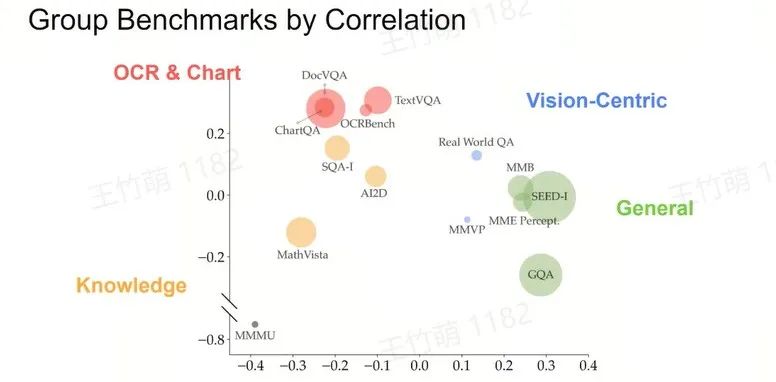
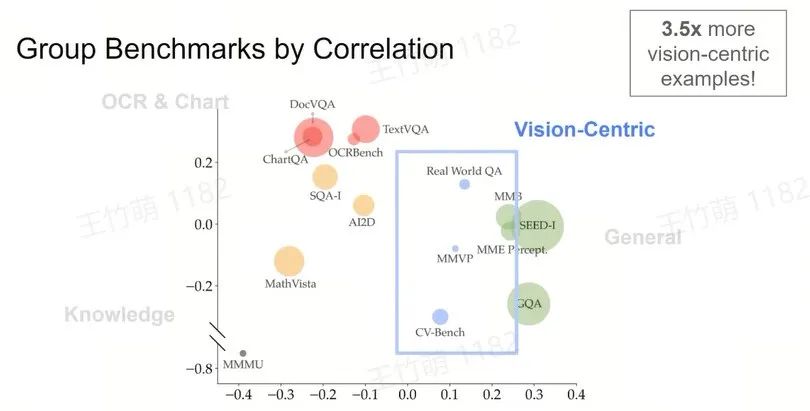
Access the "Multimodality" of the Benchmarks
Group Benchmarks into Clusters




我们关注国内外最热的创新创业动态,提供一站式的资讯服务,实时传递行业热点新闻、深度评测以及前瞻观点,帮助各位创业者掌握新兴技术趋势及行业变革,洞察未来科技走向。
你好,我是AI助理
可以解答问题、推荐解决方案等

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论