
Scaling Law,即规模法则。大模型的 Scaling Law 发展历程表明,随着模型规模、训练数据和计算资源的增加,模型性能会得到显著提升,并且这些关系遵循可预测的模式。但同时也遇到了数据受限等问题,业界对此提出了重复数据与合成数据两种方式,由此也带了许多启发。⬇️ OpenAI 首次提出大模型中的 Scaling Law ⬇️ DeepMind 改进 Scaling Law 公式 ➡️ 数据受限下的 Scaling Law(重复数据、合成数据)1.1 Scale: The Universal Laws of Life, Growth, and Death in Organisms, Cities, and Companies(Geoffrey West,2017)
Scale 提出了复杂系统中的简单法则,即Scaling law。Scaling law 是一种描述系统随着规模的变化而发生的规律性变化的数学表达,这些规律通常表现为一些可测量的特征随着系统大小的增加而呈现出一种固定的比例关系(比如幂律分布)。幂律分布:许多现象在不同尺度下都遵循幂律分布的规律,即某些变量的分布呈现出指数级增长或下降的关系(如动物代谢率与其体重的关系,城市专利数量与人口的关系)。自相似性:系统在不同尺度下具有相似的结构和行为。这种自相似性使得我们可以通过局部的观察来推断整体的性质,从而更好地理解复杂系统的运作方式。(一些很复杂的系统往往基于一些非常简单的规则,如 GPT2-GPT3的模型性能飞跃)1.2 Scaling Laws for Neural Language Models(OpenAI, Kaplan et al., 2020)原文链接:https://arxiv.org/pdf/2001.08361
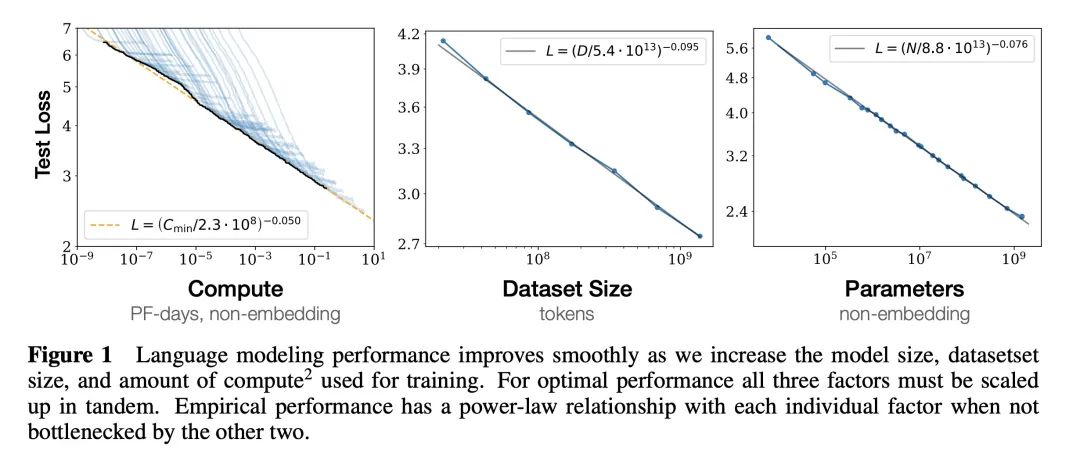
图1说明了模型性能随着模型参数量、数据量和用于训练的计算量的指数级增加而平稳提高。Loss(L):交叉熵损失,L越小大模型性能越好
Compute(C):计算量,浮点运算量FLOPs
Data(D):数据大小,token数
Parameter(N):模型参数量
式(1.5)说明了 Loss(L)、Data(D)、Parameter(N)之间关系。对于计算量(C),模型参数量(P)和数据大小(D),当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系。
1.3 Training Compute-Optimal Large Language Models(DeepMind, Hoffmann et al., 2022)原文链接:https://arxiv.org/pdf/2203.15556
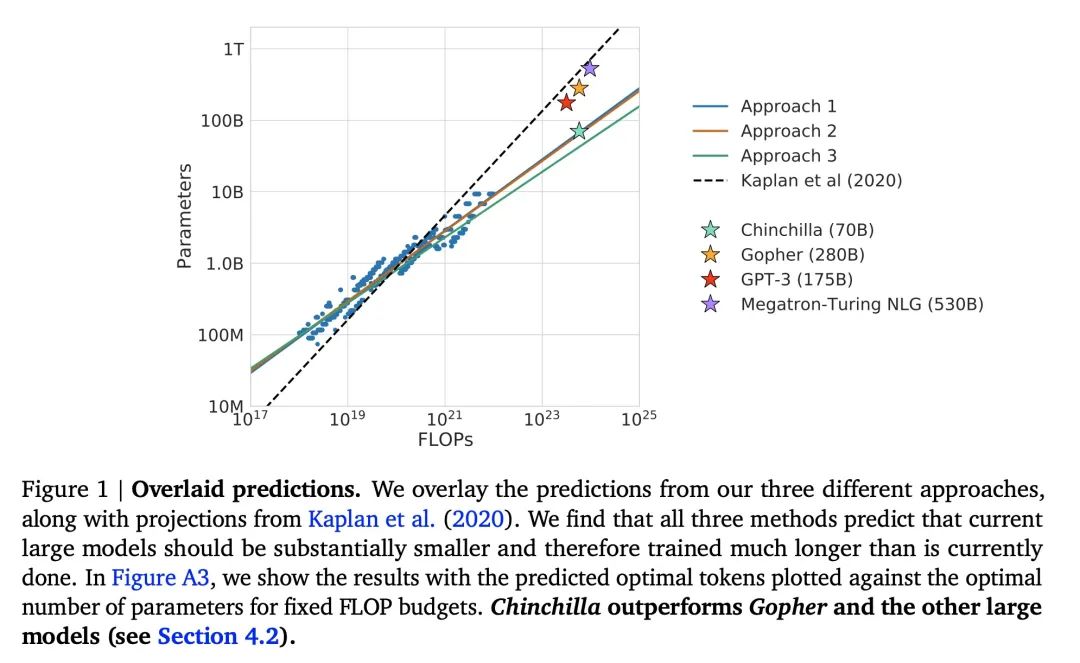
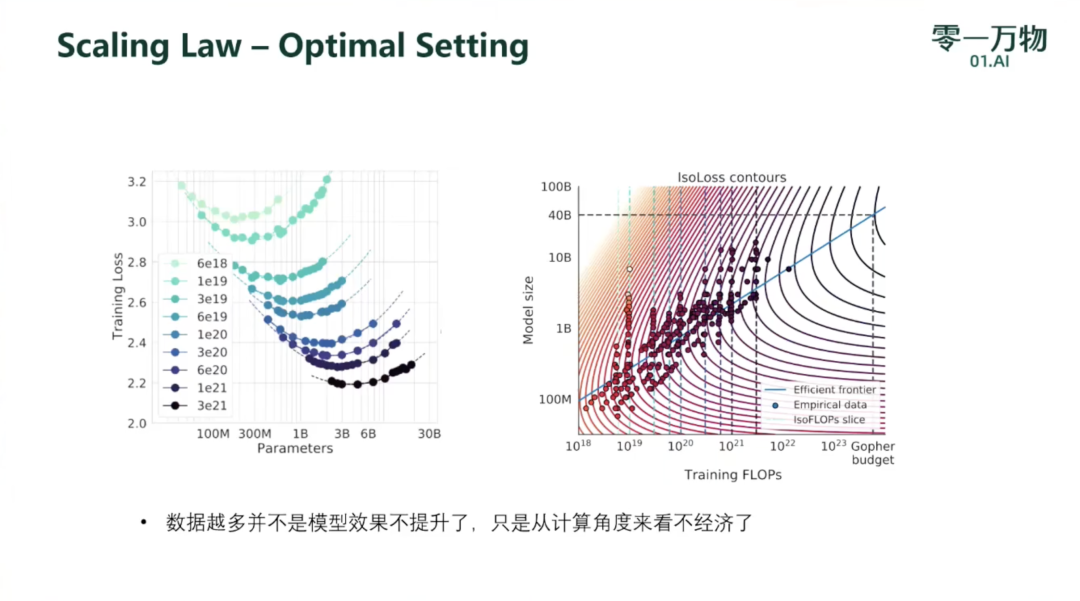
Kaplan et al.(2020) 的一个结论是,不应该将大模型训练至最低的可能loss来获得计算最优。虽然我们得出了相同的结论,但我们估计,大型模型应该在比他们建议的更多的训练tokens上进行训练。具体而言,考虑到计算预算增加10倍,他们建议模型的规模应增加5.5倍,而训练tokens的数量只应增加1.8倍。相反,我们发现模型规模和训练tokens的数量应按相同比例扩展。图1通过三种不同实验方法对模型参数量和计算量关系的预测,Approch1 ~ 3分别代表文中的3种实验方法。与Kaplan等人的预测相比,三种方法都指出当前的大型模型应更小。基于上述分析,Gopher (280B) 模型的最优大小应该在 40B ~ 70B 之间,于是按模型大小的上限 70B 使用 1.4T tokens 训练了模型Chinchilla,在多个下游任务上的性能都超过了 Gopher。为了得到缩放定律,论文中进行了大量实验(固定模型规模,在大量不同规模的数据上训练,以及固定计算量,改变模型和数据规模)通过式(2)拟合模型规模(N),训练tokens数量(D)和模型损失L之间的关系。最后得出的结论是,α≈β,即N和D应该按相同的比例缩放以进行计算最优的训练,模型大小每增加一倍,training token的数目也应该增加一倍。这项工作说明了怎么在 compute 有限的情况下,最优地分配数据和模型参数,更新了N和D的关系。
1.4 拓展:SITUATIONAL AWARENESS: The Decade Ahead(OpenAI 超级对齐部门的前负责人 Leopold Aschenbrenner, 2024/06)
原文链接:https://situational-awareness.ai/
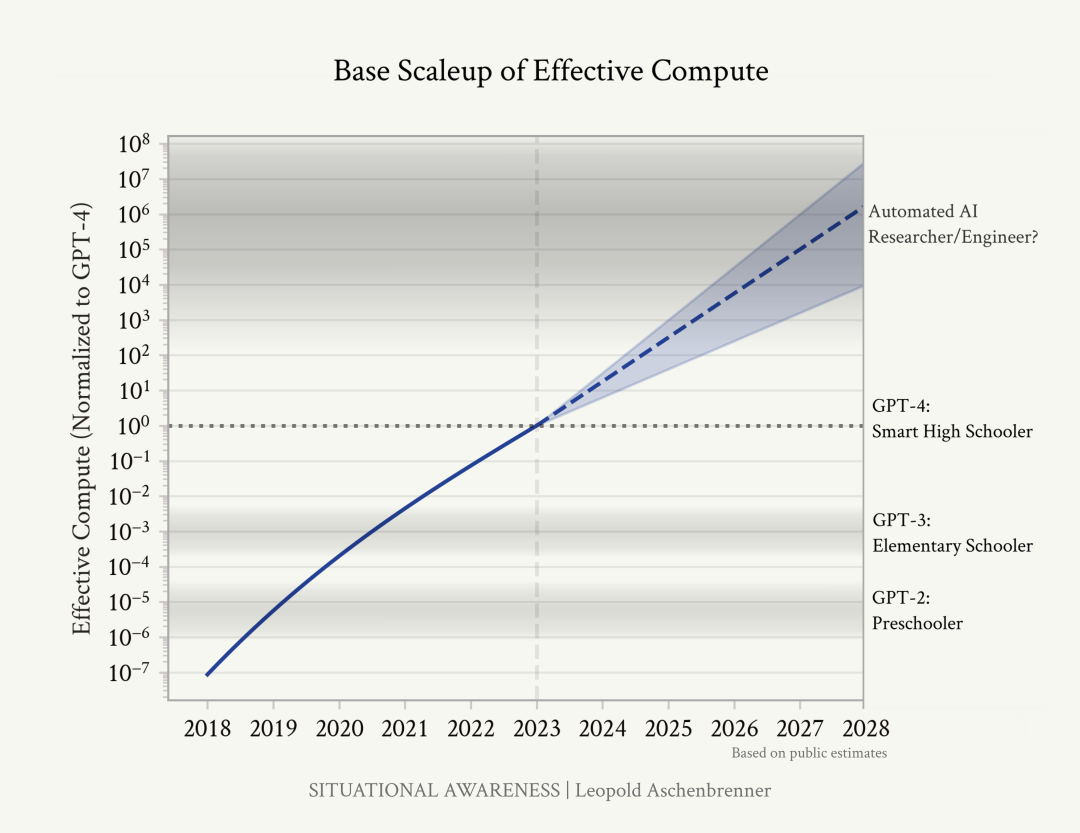
上图是作者关于有效计算扩展的粗略预测:我们在这个十年内快速穿越了计算量的数量级增加;在2030年代初之后,我们将面临缓慢的进展。计算能力的提升:讨论了计算集群规模的迅速增长,从十亿美元到万亿美元,以及为满足这些需求而进行的能源和电力合同的争夺。
人工智能的发展:预测到2025/26年,机器智能将超越大学毕业生,到本世纪末,将出现真正的超级智能。
国家安全和国际竞争:分析了超级智能可能带来的国家安全问题,以及中美之间在AGI竞赛中可能的对抗。超级智能的出现可能会导致激烈的国际竞争,甚至是战争。
技术挑战:探讨了实现AGI过程中的技术挑战,包括构建万亿级计算集群、确保AI实验室的安全、超级智能的对齐问题以及自由世界在这场竞赛中的优势。
项目展望:预计到2027/28年,AGI可能出现,并且这种发展将带来巨大的社会和经济变革。文章还讨论了实现AGI的挑战,包括构建万亿级计算集群、确保AI实验室的安全、实现AI系统的可靠控制,以及维护自由世界的优势。作者提出,为了应对这些挑战,政府和企业需要合作,以确保AI的发展能够造福人类。
未来展望:提出了对未来的一系列预测,包括对AGI的期待、可能出现的挑战,以及应对这些挑战所需的全球合作、超级智能的出现、对经济和军事的影响,以及人类如何适应这种变化。
1.5 拓展:模型训练方法论及Yi-Large的实践(零一万物,2024)
https://www.bilibili.com/video/BV1W1421C7Uy/?share_source=copy_web https://zhuanlan.zhihu.com/p/709900395
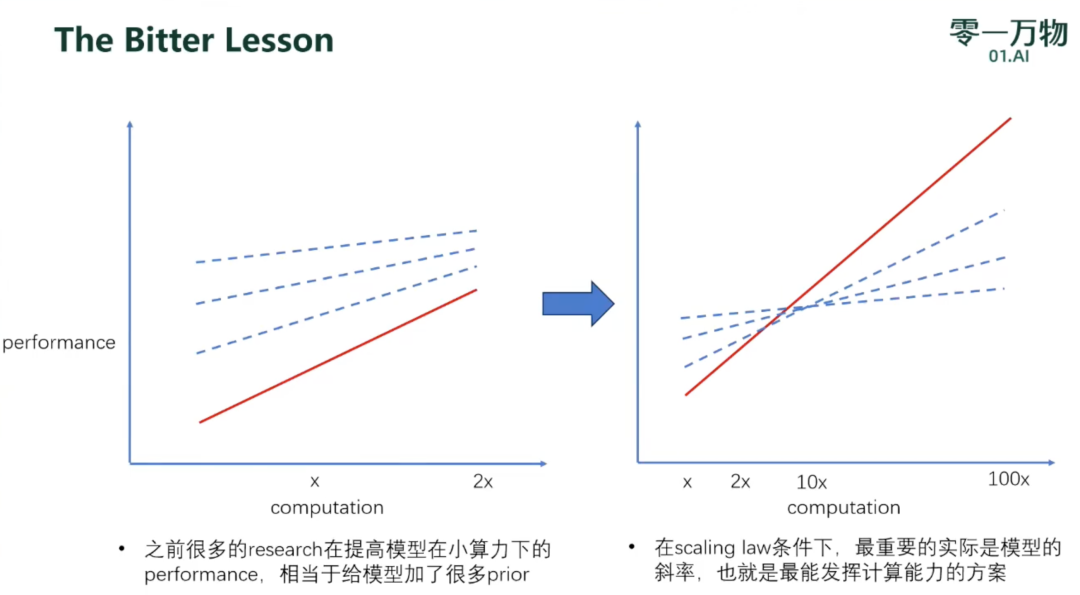
该公式的三个主要作用:(1)首先,这个公式在形式化上对广义scaling law进行了建模,N和D是两个变量,其他都是需要拟合的参数,所以N越大,Loss越小(模型能力越强);同理,D越大,模型能力越强。(2)其次,在给定compute(算力)条件下,可以根据该公式选择最优的数据和模型参数分配。这里还要用到一个简单的compute估计公式C=6ND。当给定训练FLOPs的时候,就可以根据这两个公式得到loss最小的组合。这里常常会有人argue说llama3用了远超过8B模型所能承载的数据,是不是说明scaling law不work了。首先,最优参数估计只是在给定计算条件下的loss最优,当参数量固定,数据量上升的时候,根据scaling law,loss肯定是会更小的,只是compute变更大了(不满足compute optimal中compute固定的假设)。其次,训练compute和推理compute是不一样的概念。训练中的compute optimal,举个简单的例子,如果有4倍算力,扩两倍的数据和两倍的模型参数效果比单纯扩4倍数据要好。但推理中的compute optimal则是模型越小越好。但训练是一次性消耗,推理是长期的消耗。因此,现在的模型越来越考虑推理效率,通过数据量来弥补模型小带来的差距,花更多的compute在训练上,来保证推理时又有好的性能又有低的成本。(3)最后,这个公式在预训练中最大的作用是预测loss。因为除了N和D之外,其他都是需要拟合的参数,我们只需要在N和D都比较小的时候无限打点,用一点点算力就可以得到一个可以预测比较大模型loss的scaling函数了。要注意这里的loss是收敛loss,不是所有数据训练完的loss。再分享两个小tricks:①实践中我们的做法会固定数据来进行拟合,这样loss可比性更强;②拟合的时候通常会做到最后要训练的模型十分之一的size,不然用特别小的模型打点拟合出来的系数放大几千倍以后容易失真。基于 scaling law 的可预测性又可以做很多模型结构探索、训练方法探索的比较。比如大家非常关注的Mamba,RWKV,transformer,只要比较拟合的时候哪个系数更大,模型loss就更小,效果就更好。再比如我们做结构变化的时候,不同的normalization,不同的optimization方法都可以用scaling law拟合来比较,就不用担心小模型的结论不能推广到大模型上了,因为scaling law比较的是趋势,很多在小模型上比较好的方法是由于斜率低,当模型变大就不管用了。2. The Bitter Lesson
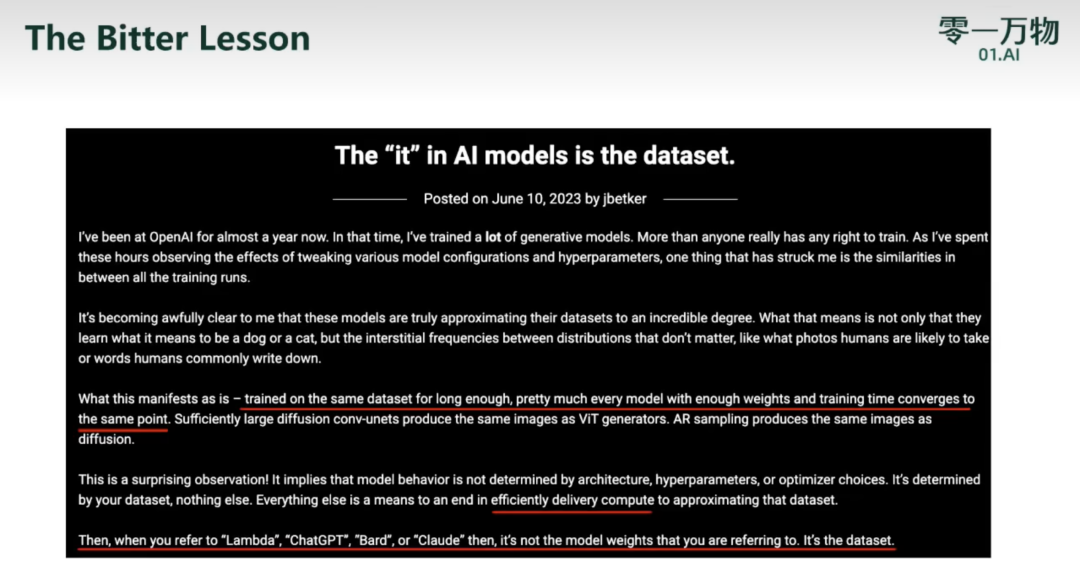
“不要雕花”:同一个数据集,训练足够长的时间(算力无限),不同架构模型都能收敛到一个点,区别只在于收敛速度(对算力的使用效率);决定模型能力的是数据而不是别的东西。三条路径:
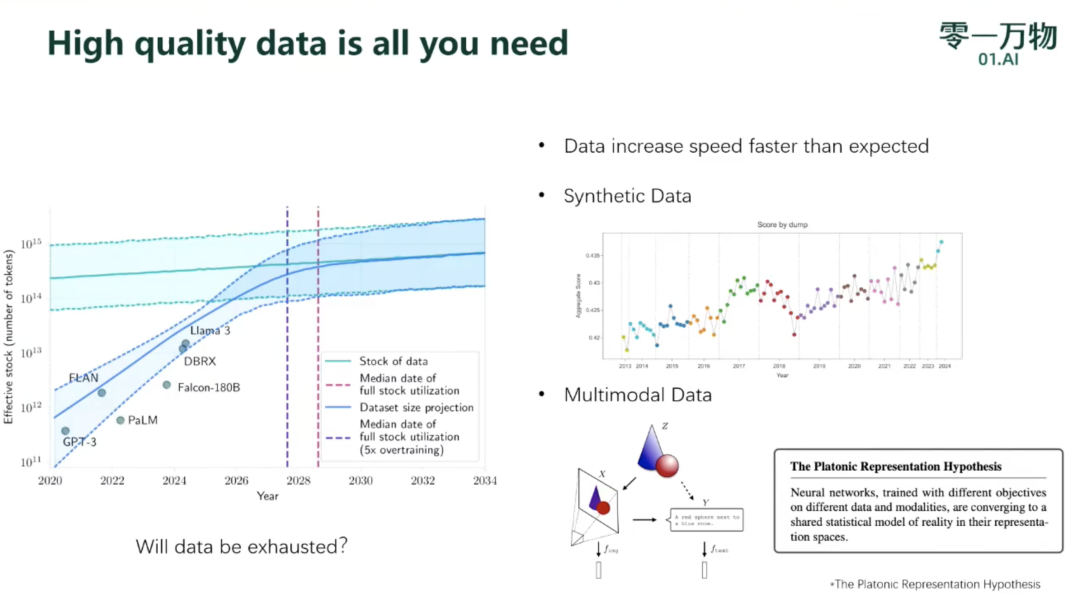
(1)数据增长速度大于预期
(2)合成数据
(3)多模态数据:更接近真实信息
原文链接:https://arxiv.org/pdf/2305.16264
https://zhuanlan.zhihu.com/p/640742782
2.1 研究目标
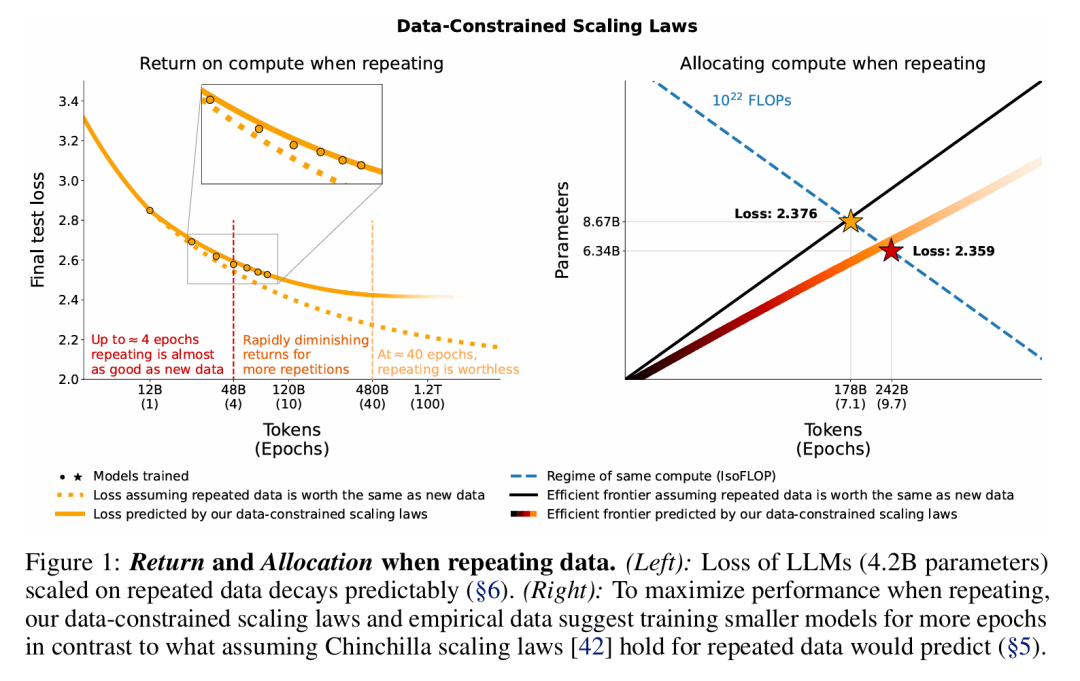
当前的LLMs在预训练时基本只在训练tokens上训练一个epoch,根据Chinchilla提出的缩放定律,要实现最佳计算利用率,模型规模和训练的tokens数量应该以同等规模增加。但可用数据有限,本文主要的目标是量化在数据受限的情况下,重复训练多个epochs对结果的影响,以便帮助研究人员在缩放模型时决定如何分配计算资源。研究做了大量的实验,通过改变数据重复程度和计算预算,实验结果如图1所示:
(1)4个epoch为临界点:考虑最佳计算利用率,给定模型参数,在较少的唯一数据(tokens数量等于X)上重复训练4个epoch,相较于在足够多的唯一数据(tokens数量等于4X)上训练1个epoch,模型在验证集上的损失变化可以忽略不计。然而,随着更多的重复,增加训练epoch的价值最终衰减为零。
(2)不考虑计算预算,在数据受限的情况下,扩大参数规模和增加训练epoch对模型训练都是有帮助的,并且epoch的缩放速度应该更快一些。
(3)文章还考虑了几种有效的数据补充方法,包括在数据集中增加代码以及放松数据过滤。2.3 研究方法
版权声明:
创新中心创新赋能平台中,除来源为“创新中心”的文章外,其余转载文章均来自所标注的来源方,版权归原作者或来源方所有,且已获得相关授权,若作者版权声明的或文章从其它站转载而附带有原所有站的版权声明者,其版权归属以附带声明为准。其他任何单位或个人转载本网站发表及转载的文章,均需经原作者同意。如果您发现本平台中有涉嫌侵权的内容,可填写
「投诉表单」进行举报,一经查实,本平台将立刻删除涉嫌侵权内容。
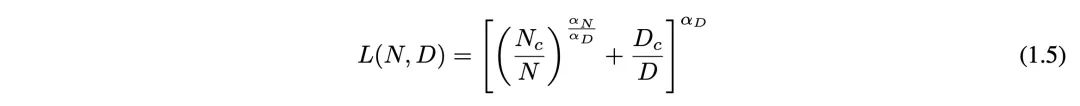





 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍