The following article is from 靖亚资本 Eminence Author 靖亚资本
靖亚专注早期投资,深信中国未来在企业数字化转型及数字经济的巨大机会,重点关注云计算、人工智能、大数据、产业数字化、金融科技等企业服务领域的投资机会。


想象一下,你向一个大语言模型(LLM)咨询如何制作完美的披萨,却被建议使用胶水来帮助奶酪粘合 — 或者看着它在普通初中生都不会犯的基本算术上出错。这就是当今生成式AI模型的局限性。
历史告诉我们,技术进步从来不是一条直线。难以察觉的知识和技艺积累遇到了火花,使创新爆发,而最终会达到一个停滞期。在过去几个世纪所有的创新都有一个共同的模式,那就是S曲线。例如:
传输控制协议(TCP)/ 互联网协议(IP)综合了1960年代的几项创新。在1973年首次发布后,发展显著加速,它的第四版终于在1981年稳定下来,现在仍在大部分互联网中使用。
在90年代末的浏览器竞争期间,浏览器技术经历了显著改进。一个被动的终端变成了一个快速、互动且完全可编程的平台。在那之后,浏览器之间的转变相对而言是渐进的。
应用商店App Store的推出导致了2010年代初期移动应用创新的爆发。如今,新颖的移动产品已经很少见了。

01
AI 的停滞期
在这次的AI变革中我们刚刚见证了这个模式的发生。阿兰 · 图灵 (Alan Turing) 作为首批计算机科学先驱在1950年的论文中尝试探索如何构建思维机器。
七十多年后,OpenAI抓住了几十年的一些进展,创造了一个大语言模型,它在某种程度上通过了图灵测试 (Turing Test),以一种与人类无差异的方式回答问题(尽管仍然远非完美)。
当ChatGPT在2022年11月首次发布时,震惊全球。随后一段时间中,每一次其后续的发布,以及来自Anthropic、Google和Meta等其他公司的模型发布,在技术上都有了显著的提高。
但现在,每个新模型的发布却进展有限。请看OpenAI模型性能提升的图表:

MMLU是一项基准测试,旨在衡量跨越57个学科(包括STEM、人文学科、社会科学等)的知识。
尽管每个基准测试系统都有其缺陷,但显然变化的速度不再那么引人注目。现在我们需要的同时也是我们最希望即将到来的,是跳跃到下一个S曲线。
我想我们知道现在AI技术停滞的原因,以及怎样才能实现下一个曲线:获取专有数据。
02
下一个曲线:专有业务数据
现在的大型语言模型是基于互联网的公有数据进行训练的。但互联网上的公有文本训练数据早已被使用(想想Github、Reddit、Wordpress和其他公共网站)。这迫使AI公司去搜寻其他数据来源,例如:OpenAI通过Whisper转录了百万小时的YouTube视频用于GPT-4,而另一种策略是通过像ScaleAI这样的服务进行数据标注。
模型提供商可以继续沿着这条道路走下去(毕竟估计有1.5亿小时的YouTube视频),但他们不会通过这种方式逃离S曲线。提高可能是微小的,回报也在下降。合成数据是另一条途径,但它有其自身的局限性和弱点。
我们认为真正能允许人类跳跃到下一个S曲线的突破是工作中产生的数据。工作环境中的数据质量远高于用于训练目的的公有数据,尤其是与转换处理互联网的剩余信息相比 (这可能是为什么很多AI生成的内容已经被称为“垃圾”的原因)。
在工作环境中生成的产品规范、销售PPT或医学研究,比未验证的维基百科页面或Reddit帖子有价值得多,如果这些信息来自各领域顶尖专家那就更好了。
那些解锁世界业务数据的初创企业将有望创造更多价值。我们比较了顶级2C互联网应用的每个用户的平均收入(ARPU)与部分B2B应用的每个用户的价格。即使是最“面向消费者”的企业应用,如Notion,仍然比2C公司每位用户带来的收入高得多:
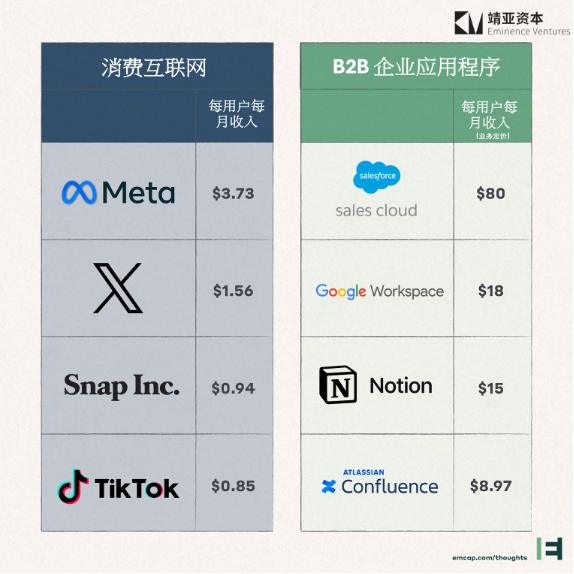
数学很简单。AI对B2B的价值潜力是巨大的,而现在这些价值很大程度上还未被挖掘。
同时,知识工作者以惊人的速度持续产生业务数据:
在2020年,Zoom捕获了3.3万亿分钟(550亿小时)的会议,这远远超过大约1.5亿小时的YouTube内容所带来的价值。
Ironclad每年处理超过10亿份文件。
Slack每周发送超过10亿条消息。
在工作环境中产生的数据将推动下一个S曲线。

03
滑坡
当大模型供应商开始解决业务用例时(参见OpenAI对Rockset的收购和Anthropic的最新发布),企业应该保持警惕。OpenAI和Anthropic称他们不会使用业务订阅的数据来训练模型。历史告诉我们,增长带来的压力可能会迫使他们食言。
以Facebook为例,Meta长期声称在用户登出账户时用户在合作伙伴网站上的活动记录不会被记录。而Meta在隐私诉讼中支付了7.25亿美元后,它仍在大规模地获取消费者数据。作为云软件的先驱,Salesforce最初承诺所有客户数据不会与第三方共享。但他们当前的隐私政策否定了这一点。
历史重演,但这次赌注会更高。随着云端的兴起,SaaS应用主要用于“非核心流程” ,任何对企业绝对核心的东西都会内部自建。随着这波AI技术的兴起,在闭源模型中输入的数据可能包括公司的所有数据,公司的知识库、内部流程、合同、个人可识别信息(PII)和其他专有的敏感数据。
这些丰富的数据构成了企业的可持续竞争优势。企业为了保护自己的利益,我们认为企业需要拥有自己的专有模型。
就像《纽约时报》在努力保护其知识产权一样,企业应抵制大型AI公司以公有数据的方式收集其专有数据。
为了充分利用其组织内部的智慧,企业应拥有自己的模型。拥有自己的模型使他们能够在保持竞争优势的同时不断改进优化。我们认为这是跳跃到下一个S曲线的正确方式。
大型AI公司正在迅速成为既得利益者,但初创企业也依然很有机会。我们已经确定了四个能帮创业企业解决AI停滞期的机会,以满足企业面临的需求和要求。
04

我们关注国内外最热的创新创业动态,提供一站式的资讯服务,实时传递行业热点新闻、深度评测以及前瞻观点,帮助各位创业者掌握新兴技术趋势及行业变革,洞察未来科技走向。

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论