不得不说,连马斯克都跳得有模有样的!
这到底是怎么一回事?
原来,是有人借助了阿里之前走红的AI技术——AnimateAnyone,生成出来了这个舞蹈片段。
技术圈的盆友对这个技术都不陌生,“出道”至今仅仅1个月时间,这个项目便已经在GitHub上斩获了超1.1万个star。
就在刚刚到来的 2024 年,阿里通义千问 APP 上线图片生成舞蹈功能,用户只需要输入一张图片,就能生成爆款舞蹈视频。
而且,免费!
不管是科目三,还是鬼步舞、兔子舞…… 练习时长无需两年半,通义千问分分钟帮你搞定。有了它,让你瞬间变身舞蹈达人,再也不用担心自己没有舞蹈功底了。
上手步骤
打开通义千问 APP,在对话框中输入「全民舞王」或者「通义舞王」。
在弹出的界面中就可以体验了!
该功能一经上线火爆国内外,在 AI 圈可谓是掀起了一波全民热舞小高潮,众多研究者纷纷玩了起来。X(原推特)上关于这项研究的浏览量动不动就上万。
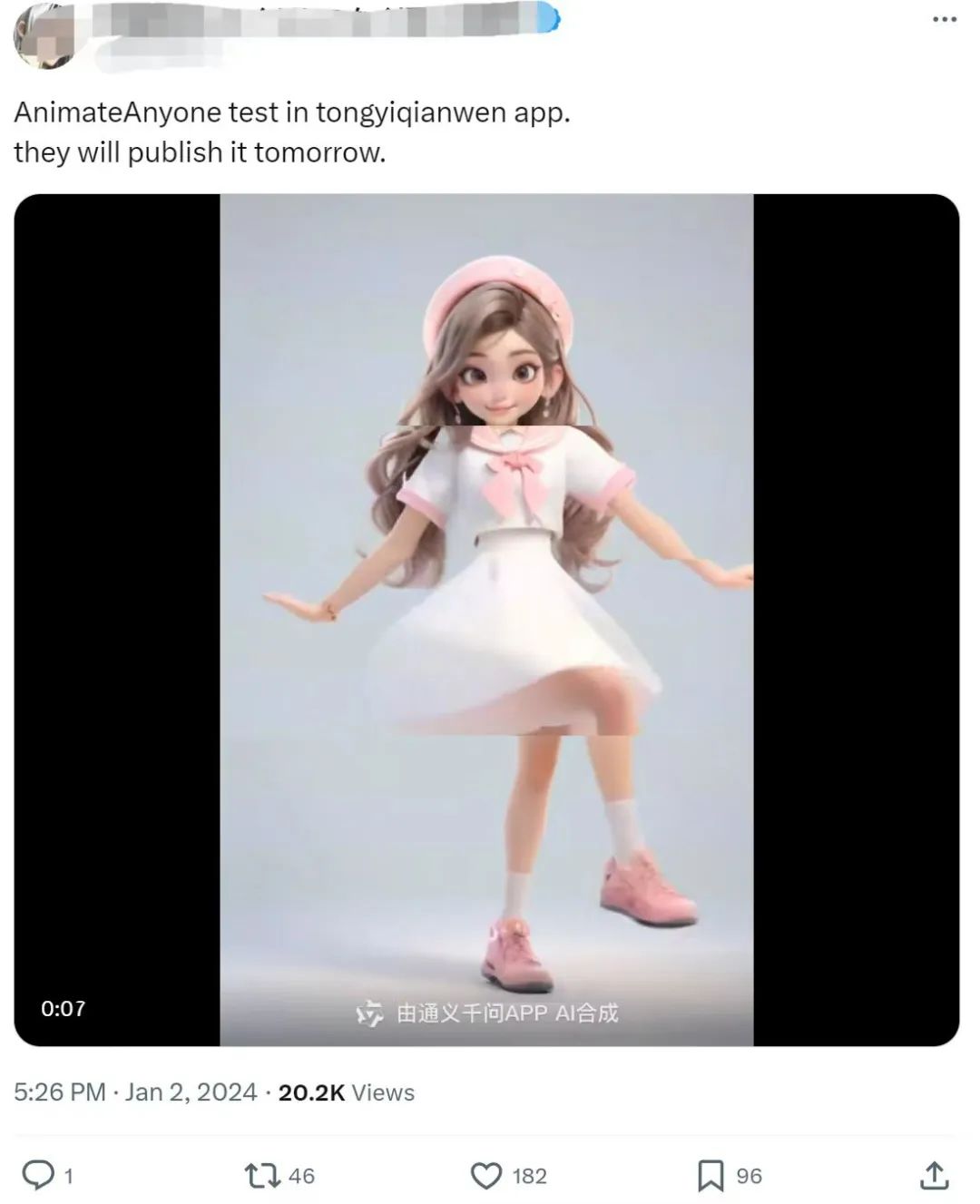
不用自己出镜,上传照片就能化身舞王,这样的黑科技谁不想试一试呢。隔壁小朋友都羡慕哭了。
不管是二次元、三次元,不管是真人、纸片人,甚至是雕塑,通义千问都能让他们舞起来,简单到只需三步:
第一步选择自己喜欢的舞蹈种类。
通义千问 APP 内置了不同的舞蹈模板,包括科目三、鬼步舞、DJ 慢摇、蒙古舞、划桨步、兔子舞等十多种舞蹈,选择你喜欢的其中一种作为目标舞蹈。
第二步上传图片。
图片的要求是全身照、正面站立、全身无遮挡、无俯仰角,图片的分辨率不能低于 500×500。你可以现拍,也可以选择之前拍摄过的图片。此外,通义千问 APP 里还内置了照片模板供大家使用。
最后一步,点击「立即生成」就可以了。
谁能想到,生成舞蹈视频已经简单如斯。
快看,马斯克除了会跳科目三,还会跳蒙古舞!
钢铁侠跳起了极乐净土,舞蹈动作不输真人,迈着欢快的小步伐,还以为是真人扮演的呢:
玲娜贝儿则跳起西域慢摇,胯部摆动流畅,手臂在空中跟着音乐节拍不停的变化:
上线即爆火的 Animate Anyone
通义千问之所以能够生成如此丝滑的舞蹈视频,背后离不开阿里在视频生成领域的深耕。
其实在去年,阿里研究团队就提出了一种名为 Animate Anyone 的算法,论文公布之初在国内外就掀起了一波不小的讨论高潮。
短短一个月,Animate Anyone 在 YouTube 单个视频播放量已经高达 16 万次,而且这只是其中一位油管博主的视频播放量,如果统计全网,将会是一个很大的数字:
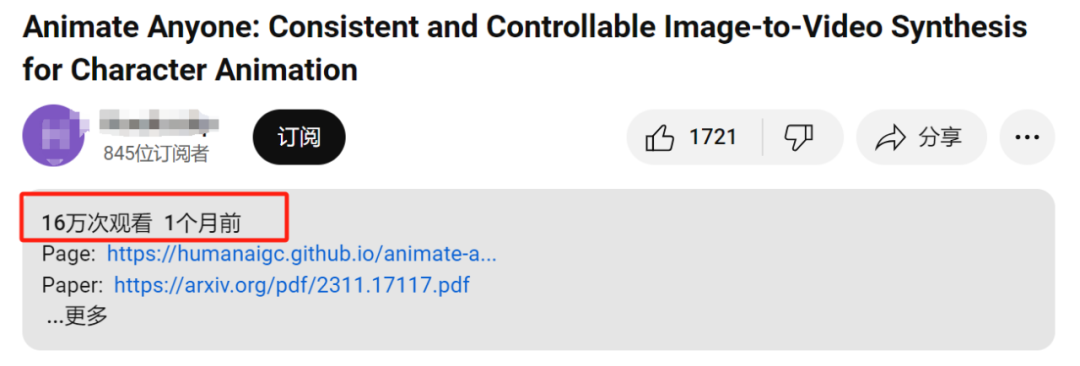
在这个视频的评论区,大家也是满屏的赞叹:「太惊人了。」「人工智能的能力太神奇了,」之后忍不住又补了一句,「真的太神奇了。」截至目前,该项目 GitHub 星标量已经达到 11 k 多。
说到视频生成,从 GAN 开始,研究者们致力于将图像进行动画化以及进行姿态迁移的探索,然而,生成的视频仍然存在局部失真、细节模糊、语义不一致和时序不连续等问题。
为了解决上述问题,阿里提出了专为角色动画量身定制的新颖框架 Animate Anyone,它能无缝地把静态图像转变成动态的角色视频。通过巧妙设计的 ReferenceNet、轻量级姿态引导器和时间建模方法,Animate Anyone 解决了图像到视频生成中的细节不一致和运动不连贯等问题。
Animate Anyone 框架如下:
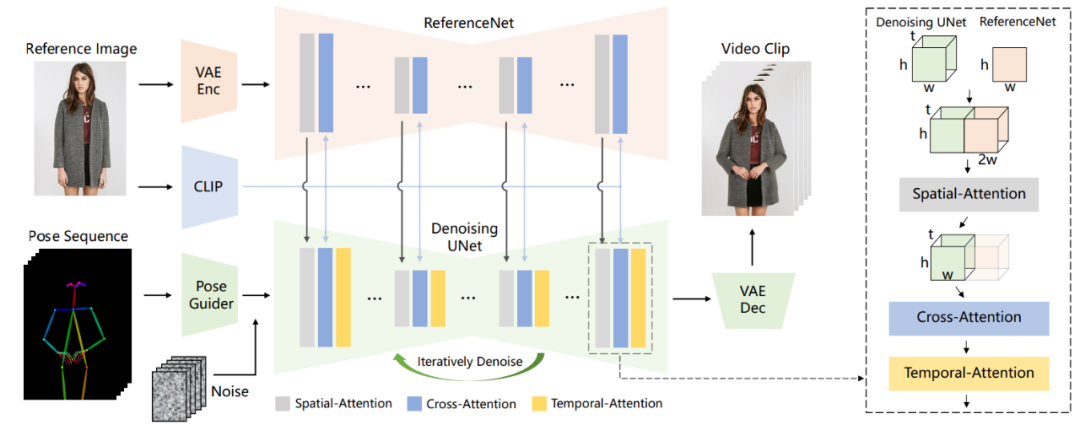
Animate Anyone 具有以下特点:
首先,它有效地保持了视频中人物外观的空间和时间一致性; 其次,它生成的高清视频不会出现时间抖动或闪烁等问题; 第三,它能够将任何角色图像动画化为视频,不受特定领域的限制。
从一致性、可控性和稳定性三个方面,保证了视频输出的效果和质量。
例如在一致性方面,阿里团队引入的是ReferenceNet,用于捕捉和保留原图像信息,可高度还原人物、表情及服装细节。
具体而言,在参考图特征提取上,ReferenceNet采用的是与去噪UNet类似的框架,但没有包含时间层;它继承了原始扩散模型的权重,并独立进行权重更新。
在将ReferenceNet的特征融合到去噪UNet时,首先将来自ReferenceNet的特征图x2复制t次,并与去噪UNet的特征图x1沿w维度连接;然后进行自注意力处理,并提取特征图的前半部分作为输出。
虽然ReferenceNet引入了与去噪UNet相当数量的参数,但在基于扩散的视频生成中,所有视频帧都需要多次去噪,而ReferenceNet只需在整个过程中提取一次特征,因此在推理过程中不会导致显著增加计算开销。
在可控性方面,阿里团队使用的是Pose Guider姿态引导器。
Pose Guider姿势引导器采用的是一个轻量级设计,而不是引入一个额外的控制网络。
具体来说,使用了四个卷积层(卷积核大小为4×4,步幅为2×2,通道数分别为16、32、64、128),这些卷积层用于将姿势图像对齐到与噪声潜变量相同的分辨率。
处理后的姿势图像会被加到噪声潜变量上,然后一起输入到去噪UNet中,从而在不显著增加计算复杂性的情况下,为去噪UNet提供姿势控制。
最后是在稳定性方面,阿里团队引入的是一个时序生成模块。
时序层的设计灵感来源于AnimateDiff,通过在特征图上执行时间维度的自注意力,以及通过残差连接,其特征被整合到原始特征中。
同样的,这个模块的作用之下,满足了在保持时间连续性和细节平滑性的同时,减少了对复杂运动建模的需求。
最终,在AnimateAnyone的加持之下,从效果上来看,保证了图像与视频中人物的一致性。
通过上述示例可以看出,由 Animate Anyone 驱动的视频生成技术,更好的保持了时序上的连续以及合理性,视频中人物的动作丝滑连接,没有跳跃或不自然的变化;生成的视频质量也非常逼真,人物的图像与视频内容能够保持高度的一致性;此外,视频的风格和色彩与原始图片一致性也较高。
从去年年末到现在,不知道大家有没有发现,AI圈都在死磕AI视频生成技术,纵观去年一整年的AIGC发展的脉络,AI视频生成的爆发趋势似乎越来越明确了。
国外如 Runway 升级了 Gen-2 模型,带来了电影级别的高清晰度;Meta 发布视频生成模型 Emu Video,其视频的动态性比 Gen-2 有明显的提高;经典的文生图模型 Stable Diffusion 的公司 Stability AI 也发布了视频生成模型 Stable Video Diffusion (SVD) 等等。国内也在迎头赶上,如字节发布 Magic Animate,华为提出的 Animate124 模型等,都在视频生成领域进行不断的创新。
同样的,阿里也在视频生成领域交出了一份满意的答卷,将 Animate Anyone 集成到通义千问 APP,使得人人都可以进行无门槛的舞蹈合成,或许用不了多久,这一轮 AI 突破带来的变革将会触及更多人,我们将见证生成式 AI 对生产力和创新的颠覆。
在这场变革中,我们相信阿里会带来更多令人惊叹的应用。
你好,我是AI助理
可以解答问题、推荐解决方案等

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论