
虚拟人,也称为数字人,通过3D建模打造形象,结合AI、MR技术、实时渲染、云计算等技术手段,可以让虚拟人实时互动。早期,虚拟人更多应用在动画游戏领域,随着AI深度学习的突破,虚拟人技术不断进步,创业者们开始了更多的商业化尝试。
近两年,市场的需求也已经不再满足于一个好看的模型,如何赋予虚拟人更真实的“生命力”是创业者们一直在探讨的话题。中科深智选择以虚拟人开发中最重要的“表情和动作生成”作为突破口。
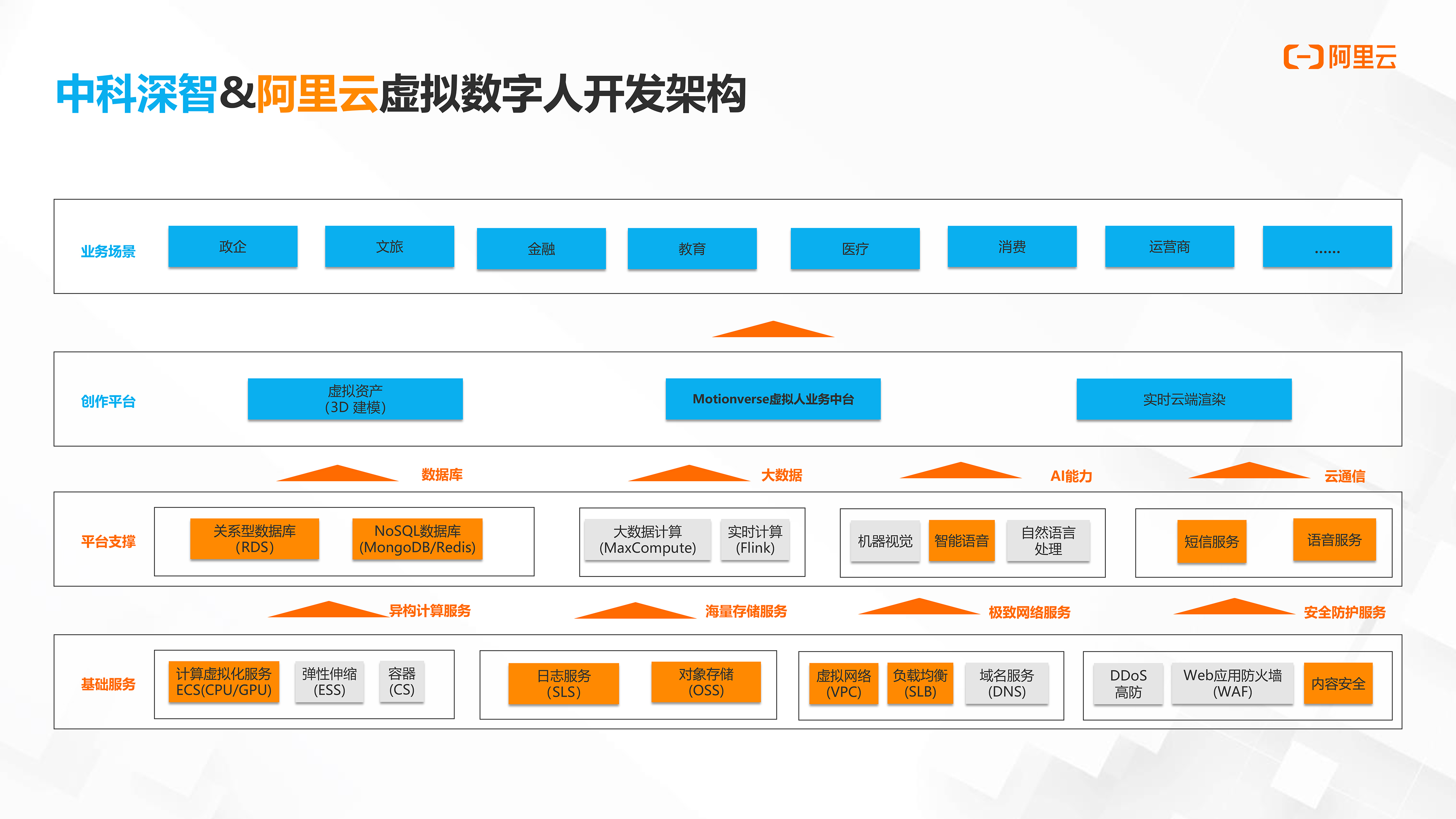
中科深智聚焦虚拟人动作和表情的实时生成,以深度学习支撑的多模态驱动引擎为核心,结合模型资产处理、虚拟人渲染技术,自主研发了虚拟人业务中台系统Motionverse,开发了元宇宙电商产品——自动播、3D AIGC动画视频创作平台—— 自动画、高效的虚拟人实时交互产品——云小七等产品。
Motionverse可提供SDK和管理后台,解决产品和终端问题。主要向零售、政务、金融、文旅、传媒、游戏、医疗、教育、运营商、制作等多行业、多场景提供解决方案,赋能数字人产业发展。
中科深智在为元宇宙和数字人产业发展赋能过程中,为加速多行业、多场景应用布局和降本增效,正积极探索云服务模式,目前采用纯云端的产品服务架构,与阿里云等服务商展开合作,除了基础云产品的使用,还引入云渲染、云计算等产品。
阿里云一直关注着中科深智的“云模式”,在智能语音、语音交互、AI算法等技术上一直保持着密切的交流。阿里云为中科深智打造了让虚拟人“发声”的数字云解决方案,基于其虚拟人业务中台系统,提供语音合成TTS服务,可以实现高拟真度、灵活配置,让虚拟人逼真发声,配合真实的表情和动作,能够进一步提升用户的真实感和沉浸感。
目前,中科深智在电商虚拟人直播市场的占有率已经达到70%多,在电商领域已经相对发展成熟,而中科深智的探索从来不止电商。他们正积极完成标准化工具的集成和输出,以及在更多场景的应用下,如何确保虚拟人的实时与互动真实感。
这个过程中,应当如何看待元宇宙的应用趋势?在技术上有哪些关键的突破口?目前已形成了怎样的产业生态?虚拟人厂家又将如何提供更实时、简单、低成本的虚拟人服务?
第10期云谷创新谈,邀请了北京中科深智科技有限公司创始人兼CEO 成维忠,一起对谈虚拟人的技术发展和产业生态,在移动互联网、游戏、元宇宙领域创业多年的他,结合自身的创业经历与行业洞察,与阿里云进行深入探讨:
(以下是对谈精选,由阿里云整理)
一千个人脑子里有一千个对“元宇宙”的理解,您对元宇宙的构想是怎样的?虚拟人又在元宇宙中扮演什么样的角色?
元宇宙不是一个凭空出现的事物,它是继互联网、移动互联网发展之后,由人对于信息获取的客观需求推动产生的。
没有互联网的时候,人们依赖面对面交流,这种信息获取的形式在交流形式中占了80%,获取的方式是基于直觉的获取。到早期互联网时候,交流变为以文字为主,对于信息的获取主要依赖大脑的想象。发展到今天,各种视频直播的兴起,让信息获取变得直观,当这种形式到达顶峰后,就需要进行新的信息革命,就诞生了“元宇宙”的概念。
元宇宙是对现实世界的映射,同样离不开“人、货、场”的概念。在元宇宙中,主要的工作有三点:第一,场景的搭建,即如何产生虚拟的场景;第二,如何把生命体搬到这个元宇宙里,包括人、动物等;第三,把更多的物品搬进来。
从技术的成熟度和经济效益来看,“场”已经形成了成熟的产业链,比较难去突破;“货”因数量多造价高等问题,还处在探索的阶段;而虚拟人从造价和市场需求量来看,发展前景可观。
中科智深定义为“多模态实时驱动虚拟人公司”,请介绍下什么是“多模态实时驱动”的“虚拟人”?
这里面主要包含了两个概念:实时和多模态。
虚拟人的技术流派主要分2D和3D两种,从发展来看,未来会以3D技术为核心,而2D技术更多作为一个补充。与动画制作相似,虚拟人的开发主要分为前期模型制作、中期处理动作和表情、后期渲染三部分。
从工作量上看,前期和后期的占比大概在20%~30%,70%的工作量集中在动作和表情的处理。在数字人领域,围绕3D虚拟的所有应用,包括现在很受欢迎的AI自动生成内容(AIGC),如果没有实时的动作和表情,就很难体现真实感。
多模态的实时动作表情生成,是未来虚拟人发展的基础,也是AIGC的基础。
未来的虚拟人技术都需要基于实时来做。从过去的一些技术应用来看,比如阿凡达的电影制作,采用了非实时、离线的技术,它的视觉呈现很真实,但是无法满足我们在元宇宙中实时交互的需求。
而多模态解决的是应用层面的问题,我们从需求端出发,打通多种输入方式,接收到输入信号后,通过AI生成想要的动作和信号,可以支撑各种应用场景的需求。
中科深智的电商全平台AI虚拟直播带货产品——自动播,在终端可以看到虚拟主播介绍产品,并能和观众做问候互动。从产品的设计开发到落地运营,中科深智主要做了哪些工作?
自动播是中科智深开发的SaaS产品,商家只需要将直播的产品文案、视频、图片上传,就可以自动开播,所有的动作和表情都是系统生成的。这个过程主要依赖云端的服务。
就我所知的,国内目前只有达摩院和中科智深采用纯云端架构,大部分公司采用的是云端加本地的架构。早期我们也采用本地渲染加云端管理的架构,这样可以降低渲染成本和降低技术复杂度,也发现了很多问题,比如说系统升级问题,需要商家自行更新,否则会导致因版本落后降低体验感。面对这些商家端反馈的问题,我们开始着手纯云端的开发,其中主要面临技术的挑战,从虚拟现实的技术到云计算方面的探索,我们都跟阿里云这样的云服务商一起研究解决。
另外,我认为虚拟人直播带货只是个过渡性阶段,是整个元宇宙电商的预演。站在元宇宙的这个范畴下看,市场的需求不仅仅是一个虚拟人,里面还会涉及大量的AI、XR的需求。
如果商家想采用真人直播,那他的需求可能会变为虚拟背景。对于这些细化场景下的需求,中科深智也提供了相关的产品,如果他是真人上播,可以用我们库里的虚拟背景或者道具去做真人直播。当这个功能满足商家的需求后,他可能会进一步要求让虚拟人一起直播。所以我们不能单纯理解为只能做虚拟人直播,其实还有很多需求的延伸。
我认为这个市场是需求驱动的,商家有需求并能给他带来生产力的,我们必须要去做。中科智深也是在直播的生态和用户的需求下,去探索实现“加量不加价”,控制渲染成本的同时,增加更多实用的虚拟工具。
对于商家来说,降低成本和提升收益是最重要的,中科智深在这两端又做了哪些工作?
我认为目前虚拟人产品的成本主要集中在三大板块,分别是云服务、渲染、交互提升。
首先,从运营的角度来看,主要关注渲染成本,但是从中科深智的实际应用评估看,采用纯云端的架构,商家可选用的功能变多了,但是整体的渲染资源消耗并没有变多,所以在实际运营过程中,核心成本还是云服务的成本。
另一方面,商家在使用虚拟人产品时,非常看重交互体验。在过去提供交互服务的时候,大部分厂家采用动作库、表情库的形式,容易出现僵尸感。随着市场的成熟,虚拟人开始更多应用在线上线下互动的场景,对交互的质量要求也在不断提升。因为在真实世界中,人讲话的时候,除了嘴巴在动,肢体也会跟着动,二者缺一都会让交互体验变得很差。所以对于很多商家来说,都会遇到这样一个问题,如何让交互变得更加理论化、更加丰富。
针对这些问题,中科深智提供实时交互的动作表情生成技术方案,高效、灵活支持各类元宇宙平台产品及服务,帮助企业实现更简单、更实用、更低成本的虚拟人驱动。
虚拟人背后的产业链是怎样的?中科深智在这里扮演的角色是什么?
虚拟人的产业链是围绕着它的开发过程来延伸拓展的。相对来说,前期建模相关的产业链已经发展成熟,而中期表情动作生成、后期渲染相关的产业链还有待完善。
前期阶段,主要工作是打造虚拟人,由原画师设计,然后通过3D建模绑定。中国3D动画已经发展了20多年,全国大概有数以万计的3D动画公司和团队,在国内来说,已经形成了非常成熟的产业链。目前也出现了AI自动建模技术,但往往用在非专业和C端领域。
中期阶段,生成动作和表情。这里有很多虚拟人服务厂家进入了一个误区,尤其是部分从传统动画行业转型的公司,依赖过去的动画产业链,认为做虚拟人只是做一个3D模型,加上几条动作和表情,这就导致了实际使用中出现无法人机互动的情况,这也是目前行业内遇到的普遍问题。随着2022年各种各样虚拟交互场景的增加,大家对这个问题的认知会变得更加深刻。
我认为在虚拟人领域,需要满足交互场景所需的及时性和动作表情的质量,这个需要放在第一位去评估。从技术理念上要做一个转变,捕捉是一个传统的概念了,过去主要在动画制作中捕捉动作和表情。但在元宇宙中未来的应用中,捕捉将是一个补充性的技术。大众场景下,只能通过生成,其中动作和表情的生成难度是不一样的。
捕捉里面动作捕捉比较容易,表情捕捉比较难,而生成是反过来的,人的表情相对动作更容易生成。因为人的表情维度比较少,而动作是在三维空间中运动的,需遵循人体运动规律。因此在训练算法模型中,需要对数据分门别类,做强化学习。目前的技术很难实现,但我们可以针对一些主要场景去做强化学习和强化的数据集,另一方面,这里面要大量地加强约束。
中科智深是如何去训练这个模型的?不同场景的应用迁移中,有什么关键难点吗?
我们目前会采用一些生产性数据做基础训练,但是随着算法精度要求提高,我们很多数据都是通过专业采集而来。目前动作和表情还做不到像语言那样,做类似于ChatGPT这样的大规模数据训练。预估两到三年以后,随着整个虚拟的应用增多,数据量有一定累积后,可能会过渡到这样的大数据训练。
人的底层动作逻辑是相同的,但是要在特定的场景下实现更真实的交互,就要做一些微表情、微动作的强化训练。目前我们主要针对电商、播报、线下屏交互、娱乐等场景做强化训练,基本覆盖市场上主流的应用场景。
目前,中科深智主要在往哪几个方向应用?取得了什么进展?
主要是两大板块,一个是线下终端场景,一个APP。
首先讲线下终端场景。很多线下终端场景会放置一些交互屏,比如银行、医院,最早的时候需要人们手动按屏幕操作,对于一些不懂的老年人来说这有一定的难度。时间长了,屏幕的灵敏度也会降低。即便近几年开始应用一些云交互模块,但是还会一定程度依赖人工的操作,所以用的人也很少。
另外一个是APP,很多APP也会设置一个2D虚拟形象,但是也存在同样的问题,复杂的交互无法完成,只能实现菜单的打开和返回。而使用虚拟人,通过AI可以帮助我们完成很多的菜单交互。
我认为明年或者后年,线上线下的交互场景会成为一个潜力市场,我们目前也在往这个方向去努力。
中科深智的使命是——创造通用AI虚拟人,赋能元宇宙以“真实生命力”。这里有一个非常重要的词“通用AI”。这个让我联想到今年引起业内躁动的ChatGPT,这款由OpenAI推出的产品,在语言模型上的成熟度被称为聊天机器人的顶流。那么回到中科深智的核心技术,我们去实现通用AI虚拟人的关键是什么?
动作表情的生成在AI中是独立的领域,包括我们,国内好几家公司已经在做了。但大家关注的焦点集中在绘图方面,还没有关注到3D的生成。只有模型,没有表情动作是不行的。
对我们来说,很难一个公司完成所有的工作,关键还是要外部的合作。我们的聚焦点主要放在虚拟人的动作和表情的绑定规范工作,其它涉及算法、云服务等一些工作,会与阿里云这样的第三方服务商合作,也更有优势。
阿里云创新中心将阿里技术、产品、业务的生产力,转化为对企业发展有价值的推动力,将更普惠、更安全、更绿色的产品和服务提供给科技型中小企业,在中小企业科技创新、日常运营、职业技能培训、资金对接、跨境出海等方面提供全方位支持。
截至目前,阿里云创新中心累计为中小创企业提供2亿的双创云资源,共服务了超过350万的创业者、50万小微企业,孵化出600多家高成长创新企业,调研数据显示头部企业估值规模超1387亿,每年估值增速超过35%。

你好,我是AI助理
可以解答问题、推荐解决方案等

 个人中心
个人中心 个人信息
个人信息 我的项目
我的项目 创业通介绍
创业通介绍
评论